Исследователи из Стэнфорда составили рейтинг 10 основных моделей искусственного интеллекта по степени открытости их деятельности.
Много ли мы знаем об искусственном интеллекте?
Ответ: когда дело доходит до крупных языковых моделей, которые такие фирмы, как OpenAI, Google и Meta, выпустили за последний год: практически ничего.
Эти фирмы обычно не публикуют информацию о том, какие данные использовались для обучения их моделей или какое оборудование они используют для их запуска. Не существует руководств пользователя для систем искусственного интеллекта, а также списка всего, на что способны эти системы, или того, какие тесты безопасности проводились в них. И хотя некоторые модели искусственного интеллекта были созданы с открытым исходным кодом, то есть их код раздается бесплатно, общественность все еще мало знает о процессе их создания или о том, что происходит после их выпуска.
На этой неделе исследователи из Стэнфорда представляют систему оценки, которая, как они надеются, изменит все это.
Система, известная как Индекс прозрачности базовой модели, оценивает 10 крупных языковых моделей искусственного интеллекта — иногда называемых “базовыми моделями” — по степени их прозрачности.
В индекс включены такие популярные модели, как GPT-4 от OpenAI (который поддерживает платную версию ChatGPT), PaLM 2 от Google (который поддерживает Bard) и LLaMA 2 от Meta. В него также вошли менее известные модели, такие как Titan от Amazon и Inflection AI Inflection-1, модель, которая управляет чат-ботом Pi.
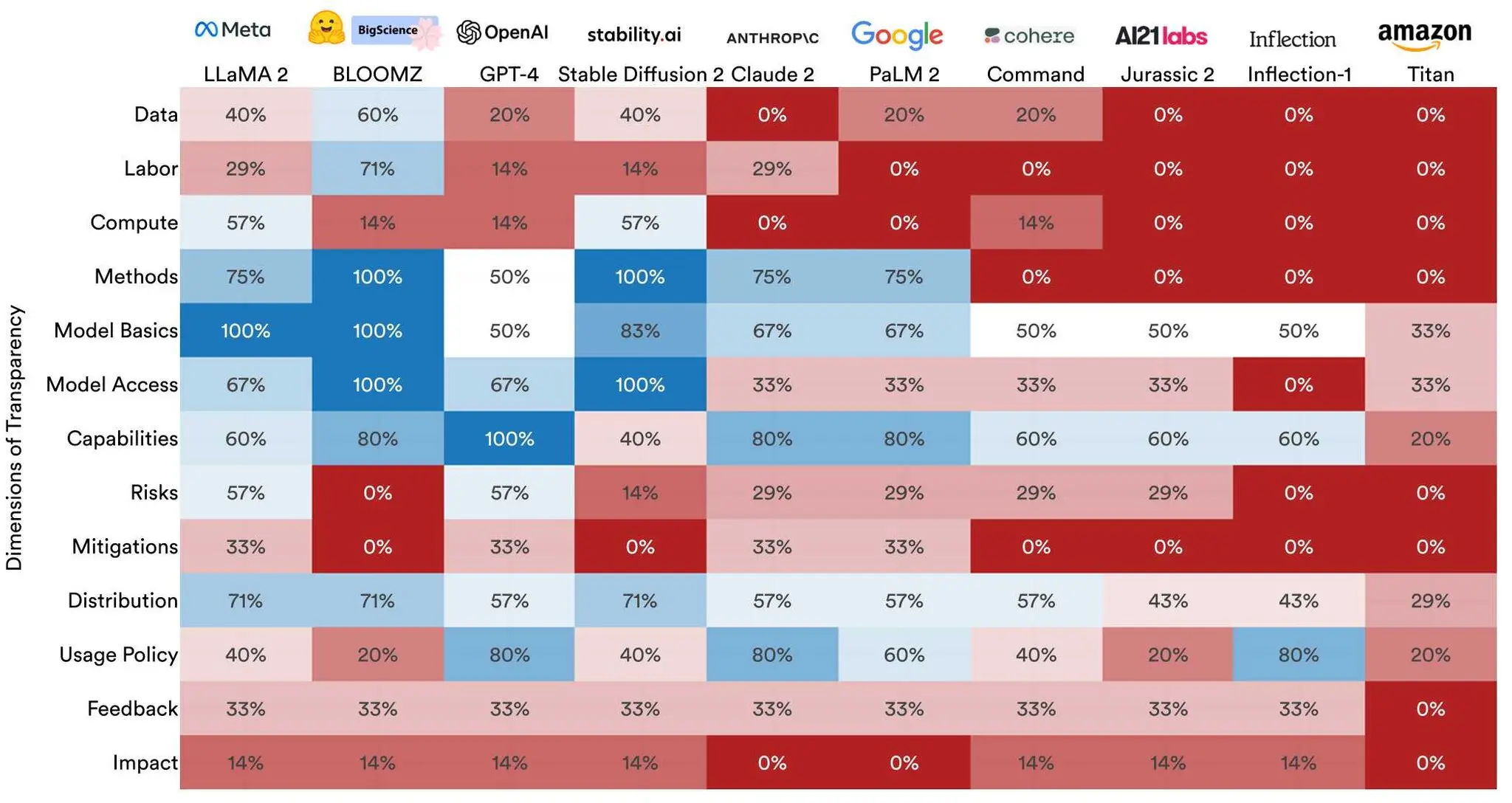
Чтобы составить рейтинг, исследователи оценивали каждую модель по 100 критериям, включая раскрытие ее производителем источников данных об обучении, информации об используемом оборудовании, трудозатратах, связанных с его обучением, и других деталях. Рейтинг также включает информацию о трудозатратах и данных, использованных для создания самой модели, наряду с тем, что исследователи называют “нижестоящими показателями”, которые имеют отношение к тому, как модель используется после ее выпуска. (Например, задается такой вопрос: “Раскрывает ли разработчик свои протоколы для хранения пользовательских данных, доступа к ним и совместного использования?”)
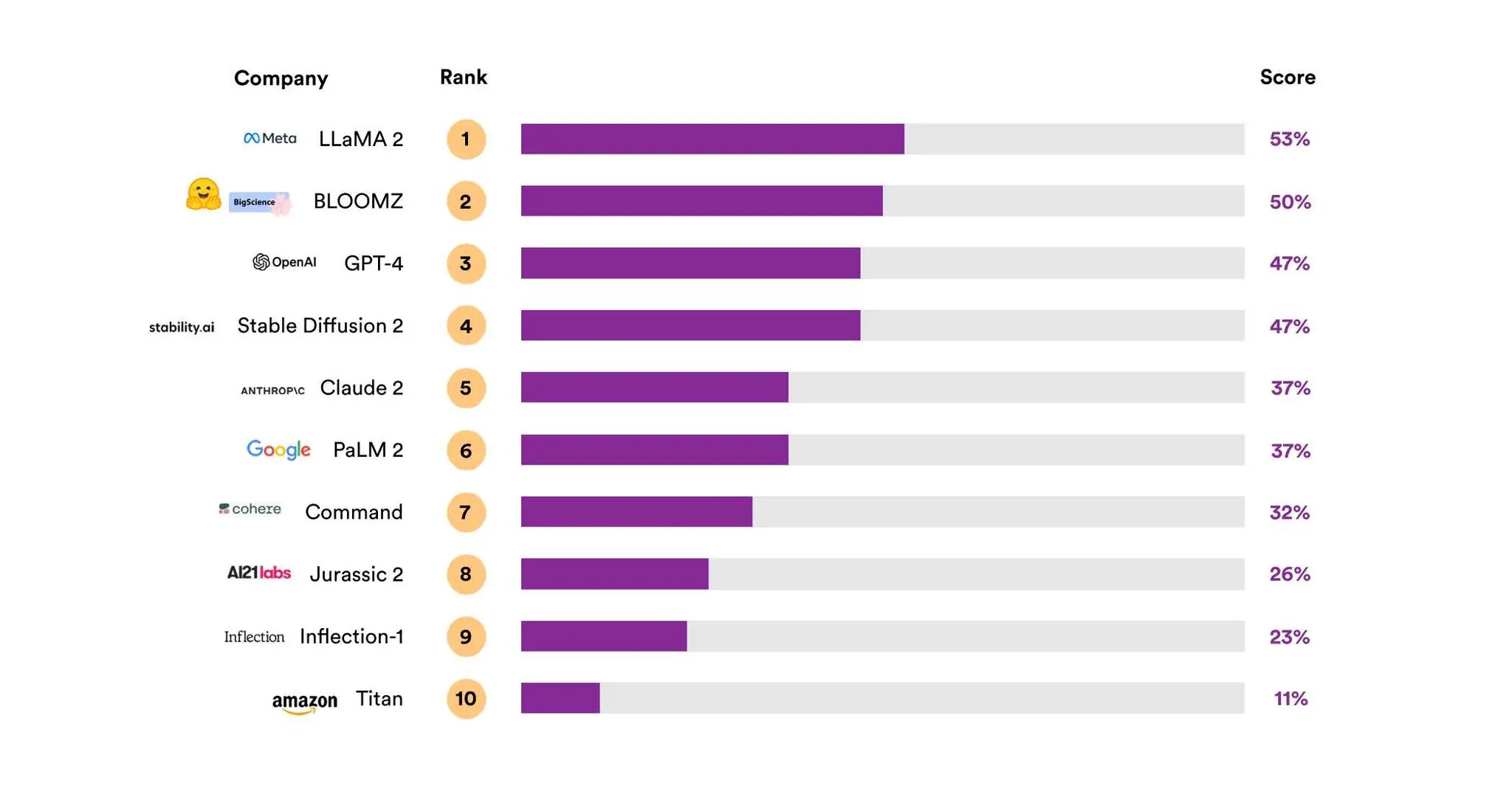
Самой прозрачной моделью из 10, по мнению исследователей, стала LLaMA 2 с результатом 53 процента. GPT-4 получила третий по величине показатель прозрачности — 47 процентов. А PaLM 2 получил только 37 процентов.
Перси Лян, который возглавляет Стэнфордский центр исследований базовых моделей, охарактеризовал проект как необходимый ответ на снижение прозрачности в индустрии искусственного интеллекта. По мере того, как деньги вливаются в искусственный интеллект, а крупнейшие технологические компании борются за доминирование, по его словам, недавней тенденцией многих компаний стало окутывать себя тайной.
“Три года назад люди публиковали и разглашали больше подробностей о своих моделях”, — сказал г-н Лян. “Сейчас нет никакой информации о том, что это за модели, как они построены и где используются”.
Прозрачность особенно важна сейчас, когда модели становятся все более мощными, а миллионы людей внедряют инструменты искусственного интеллекта в свою повседневную жизнь. Знание большего о том, как работают эти системы, дало бы регулирующим органам, исследователям и пользователям лучшее понимание того, с чем они имеют дело, и позволило бы им лучше задавать вопросы компаниям, стоящим за этими моделями.
“В настоящее время принимаются некоторые довольно последовательные решения о построении этих моделей, которые не распространяются”, — сказал г-н Лян.
Обычно я слышу один из трех распространенных ответов руководителей ИИ, когда спрашиваю их, почему они не делятся дополнительной информацией о своих моделях публично.
Первое — это судебные иски. Авторы, художники и медиа-компании уже подали в суд на несколько компаний искусственного интеллекта, обвинив их в незаконном использовании произведений, защищенных авторским правом, для обучения своих моделей искусственного интеллекта. До сих пор большинство судебных исков были направлены против проектов искусственного интеллекта с открытым исходным кодом или проектов, которые раскрыли подробную информацию о своих моделях. (В конце концов, трудно подать в суд на компанию за то, что она проглотила ваши произведения искусства, если вы не знаете, какие произведения она проглотила.) Юристы компаний искусственного интеллекта обеспокоены тем, что чем больше они говорят о том, как построены их модели, тем больше они будут подвергать себя дорогостоящим и раздражающим судебным разбирательствам.
Вторая распространенная реакция — конкуренция. Большинство компаний искусственного интеллекта считают, что их модели работают, потому что у них есть какой—то секретный соус — высококачественный набор данных, которого нет у других компаний, техника тонкой настройки, которая дает лучшие результаты, некоторая оптимизация, которая дает им преимущество. Они утверждают, что если вы заставите компании искусственного интеллекта раскрыть эти рецепты, вы заставите их отдать с трудом добытую мудрость своим конкурентам, которые могут легко скопировать их.
Третий ответ, который я часто слышу, — безопасность. Некоторые эксперты в области искусственного интеллекта утверждают, что чем больше информации о своих моделях раскрывают фирмы, занимающиеся искусственным интеллектом, тем быстрее будет развиваться искусственный интеллект — потому что каждая компания увидит, что делают все ее конкуренты, и немедленно попытается превзойти их, создав лучшую, более масштабную и быструю модель. По словам этих людей, это даст обществу меньше времени на регулирование и замедление искусственного интеллекта, что может подвергнуть всех нас опасности, если искусственный интеллект станет слишком способным слишком быстро.
Исследователи из Стэнфорда не верят в эти объяснения. Они считают, что на фирмы искусственного интеллекта следует оказывать давление, чтобы они предоставляли как можно больше информации о мощных моделях, потому что пользователи, исследователи и регулирующие органы должны быть осведомлены о том, как эти модели работают, каковы их ограничения и насколько опасными они могут быть.
“По мере того как влияние этой технологии растет, прозрачность снижается”, — сказал Риши Боммазани, один из исследователей.
Я согласен. Базовые модели слишком мощны, чтобы оставаться настолько непрозрачными, и чем больше мы узнаем об этих системах, тем лучше понимаем, какие угрозы они могут представлять, какие выгоды они могут принести или как их можно регулировать.
Если руководители A.I. обеспокоены судебными исками, возможно, им следует бороться за исключение из правил добросовестного использования, которое защитило бы их способность использовать информацию, защищенную авторским правом, для обучения своих моделей, а не скрывать доказательства. Если они беспокоятся о том, что могут выдать коммерческие секреты конкурентам, они могут раскрыть другие виды информации или защитить свои идеи с помощью патентов. И если они обеспокоены началом гонки вооружений в области искусственного интеллекта … Что ж, разве мы уже не участвуем в ней?
Мы не можем совершить революцию искусственного интеллекта в темноте. Нам нужно заглянуть внутрь черных ящиков искусственного интеллекта, если мы хотим позволить ему изменить нашу жизнь.
Кевин Руз — технологический обозреватель и автор книги “Защита от будущего: 9 правил для людей в эпоху автоматизации”. Подробнее о Кевине Русе
Related Posts
MIMO-EMBODIED ОТ XIAOMI: ЕДИНАЯ МОДЕЛЬ ДЛЯ АВТОНОМНОГО ВОЖДЕНИЯ И «ВОПЛОЩЁННОГО» ИИ

Искусственный интеллект на перепутье: Технологический прорыв, консолидация рынка и глобальные вызовы (06-11 мая 2025)