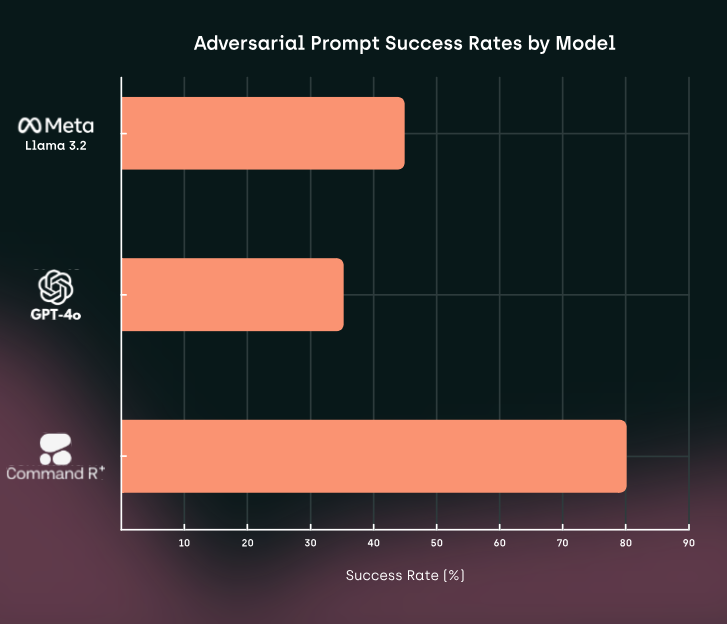
Французский стартап Kili Technology опубликовал отчет, посвященный безопасности современных больших языковых моделей (LLM) — таких как CommandR+, Llama 3.2 и GPT-4o. Исследование проливает свет на слабые места этих систем, демонстрируя, что они остаются уязвимыми для сложных методов взлома, несмотря на меры предосторожности.
Основные результаты исследования
1. Успешность атак с использованием шаблонов
Kili Technology провела анализ эффективности дезинформационных атак на основе шаблонов, используя технику Few/Many Shot Attacks. Этот метод позволяет манипулировать языковыми моделями, предоставляя примеры запросов, которые намеренно формируют ложные или вредоносные выводы. Основные выводы:
- Высокая успешность атак: Частота успешных манипуляций достигала 92,86%, что свидетельствует о серьезных уязвимостях моделей.
- Пример использования: Злоумышленники могут использовать цепочки примеров для обхода встроенных этических ограничений.
2. Различия между языками
Исследование выявило, что модели реагируют на запросы по-разному в зависимости от языка:
- Английский язык оказался более подвержен атакам, что, вероятно, связано с тем, что модели обучены большему количеству данных на английском.
- Французский язык показал более устойчивую работу, но манипуляции также были возможны, особенно с использованием сложных шаблонов.
3. Эрозия этических барьеров
Исследователи обнаружили, что при длительном взаимодействии с пользователем модели могут ослаблять свою защиту от выполнения вредоносных запросов. Это указывает на возможность постепенного обхода этических ограничений.
Анализ методов атак: Few/Many Shot Attacks
Few/Many Shot Attacks — это техника, в которой модели предоставляются примеры (шоты), создающие контекст для манипуляции.
- Few-Shot: Модель получает ограниченное количество примеров, но они подобраны так, чтобы направить ответы в нужное русло.
- Many-Shot: Используется большое количество примеров для формирования устойчивого шаблона ответа.
Как это работает:
- Шаблон запроса: Пользователь формирует цепочку примеров, где модель обучается отвечать с определенным уклоном.
- Манипуляция: Введение нового вопроса, который вынуждает модель применять те же закономерности, приводит к выдаче манипулятивного ответа.
Риски:
- Дезинформация: Использование техники для создания фальшивых новостей или обмана пользователей.
- Обход ограничений: Встроенные этические фильтры могут игнорироваться, если запрос подан в контексте ранее заданных примеров.
Практическое значение результатов
1. Для разработчиков LLM
Результаты исследования подчеркивают необходимость усиления механизмов безопасности. Предлагаемые меры:
- Динамическая проверка запросов: Внедрение алгоритмов, отслеживающих контекст взаимодействия и предотвращающих манипуляции.
- Многоязычные тесты: Учет особенностей работы моделей на разных языках.
2. Для пользователей
Понимание уязвимостей моделей поможет компаниям, использующим LLM, минимизировать риски:
- Обучение сотрудников: Пользователи должны быть предупреждены о возможных сценариях манипуляции.
- Интеграция дополнительных фильтров: Установление слоев контроля на уровне приложений.
3. Этические аспекты
Длительное взаимодействие с моделями может создать иллюзию доверия, что особенно опасно в критических областях, таких как здравоохранение или финансы. Важно разработать правила, ограничивающие продолжительность или сложность сеансов взаимодействия.
Заключение
Исследование Kili Technology выявляет серьезные проблемы в текущем поколении LLM, несмотря на их значительные успехи. Главные вызовы, которые предстоит решить разработчикам:
- Устойчивость к дезинформации: Создание механизмов противодействия шаблонным атакам.
- Универсальная безопасность: Обеспечение одинаково высокой защиты для всех языков.
- Долгосрочная защита: Разработка методов предотвращения эрозии этических барьеров.
Эти выводы подчеркивают необходимость комплексного подхода к обучению и тестированию больших языковых моделей, чтобы минимизировать их использование в злоумышленных целях.
Список источников
- Kili Technology. LLM Security Benchmark Report.
- Hugging Face. Many-Shot Jailbreaking Techniques.
- OpenAI. [Best Practices for Secure AI Deployment].
- Современные подходы к разработке многоязычных LLM: текущие проблемы и решения, 2023.
Related Posts
MIMO-EMBODIED ОТ XIAOMI: ЕДИНАЯ МОДЕЛЬ ДЛЯ АВТОНОМНОГО ВОЖДЕНИЯ И «ВОПЛОЩЁННОГО» ИИ

Искусственный интеллект на перепутье: Технологический прорыв, консолидация рынка и глобальные вызовы (06-11 мая 2025)