Современные задачи мультимодального анализа, такие как работа с изображениями и текстом, требуют мощных и ресурсоемких моделей. Однако для многих приложений, особенно тех, которые работают на устройствах с ограниченными вычислительными ресурсами, такие как смартфоны или встроенные системы, традиционные крупные модели становятся непрактичными. SmolVLM — это новая разработка в области мультимодального анализа от Hugging Face, которая сочетает в себе эффективность, производительность и компактность. Эта статья подробно рассматривает особенности модели, её применение и потенциал для различных задач.
Основная часть
1. Что такое SmolVLM?
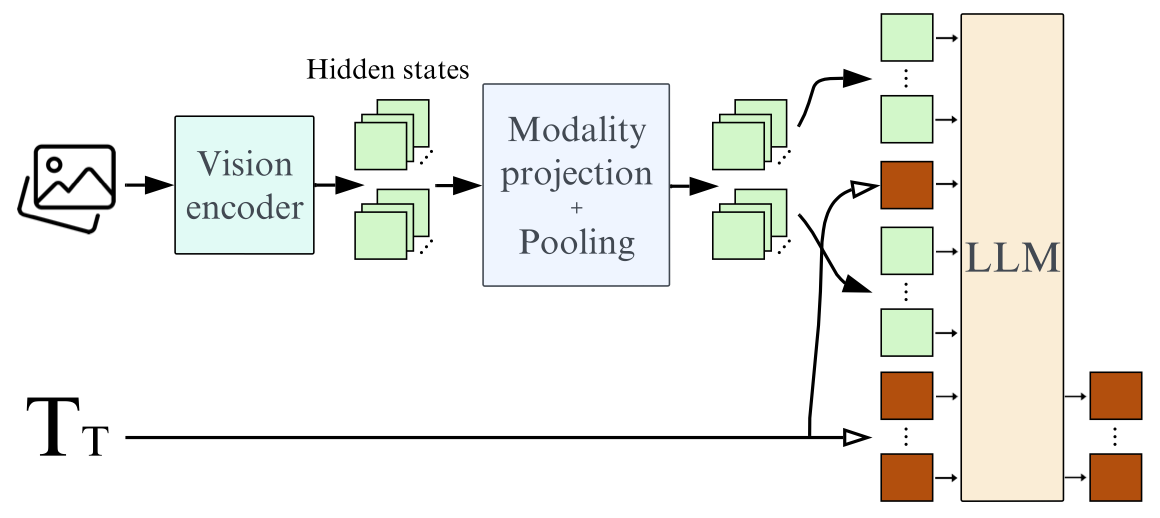
SmolVLM (Small Vision-Language Model) — это компактная модель с 2 миллиардами параметров, разработанная для обработки задач, связанных с анализом текста и изображений. Несмотря на сравнительно небольшой размер, модель демонстрирует высокую производительность, сопоставимую с крупными аналогами.
Ключевые особенности SmolVLM:
- Малый размер и высокая производительность. SmolVLM оптимизирована для использования на устройствах с ограниченными ресурсами, сохраняя при этом высокую точность.
- Многофункциональность. Подходит для задач, связанных с пониманием изображений, текста и их сочетания.
- Открытость. Модель предоставляется в открытом доступе под лицензией Apache 2.0.
2. Варианты SmolVLM
Hugging Face представили три версии модели для различных нужд:
- SmolVLM-Base. Основная версия модели для настройки и обучения на новых данных.
- SmolVLM-Synthetic. Версия, обученная на синтетических наборах данных, что делает её пригодной для специфических сценариев, где требуется меньше реальных данных.
- SmolVLM-Instruct. Модель, оптимизированная для интерактивных сценариев и задач, где требуется взаимодействие с пользователем.
Эти версии позволяют гибко использовать модель в зависимости от целей и технических возможностей.
3. Оптимизация и производительность
SmolVLM разработана с акцентом на эффективность:
- Снижение потребления памяти. Модель использует оптимизированные методы хранения и обработки данных, что уменьшает потребности в видеопамяти (GPU).
- Инновационная архитектура. Включает методы компрессии визуальной информации и улучшенные механизмы обработки изображений.
- Скорость работы. Благодаря оптимизированной архитектуре, модель демонстрирует высокую скорость обработки данных даже на устройствах с ограниченными ресурсами.
4. Применение SmolVLM
SmolVLM может использоваться в самых разных областях, включая:
- Анализ документов. Обработка изображений с текстом (например, сканированных документов) и их преобразование в структурированные данные.
- Интерактивные приложения. Модель хорошо справляется с задачами взаимодействия с пользователем в приложениях, где требуется обработка изображений и текста одновременно.
- Контекстное понимание изображений. Подходит для задач в области компьютерного зрения, где требуется учитывать текстовые метаданные или описания.
Пример использования: встраивание SmolVLM в мобильное приложение для автоматического перевода текста на изображении или добавления пояснительных описаний к фотографии.
5. Открытость и поддержка сообщества
Одна из ключевых особенностей SmolVLM — это её доступность:
- Hugging Face предоставляет инструменты для настройки модели с использованием библиотеки Transformers.
- Открытые датасеты и рецепты обучения делают процесс адаптации модели прозрачным и простым.
- SmolVLM активно поддерживается сообществом, что упрощает её интеграцию в коммерческие и исследовательские проекты.
Заключение
SmolVLM от Hugging Face — это значительный шаг вперёд в области мультимодальных моделей. Её компактность, высокая производительность и доступность делают её идеальным выбором для широкого спектра задач, от анализа документов до разработки интерактивных приложений. Благодаря открытости и поддержке со стороны сообщества, модель имеет потенциал для масштабного использования в различных сферах.
Список источников
Related Posts
MIMO-EMBODIED ОТ XIAOMI: ЕДИНАЯ МОДЕЛЬ ДЛЯ АВТОНОМНОГО ВОЖДЕНИЯ И «ВОПЛОЩЁННОГО» ИИ

Искусственный интеллект на перепутье: Технологический прорыв, консолидация рынка и глобальные вызовы (06-11 мая 2025)