1. Введение
С распространением больших языковых моделей (LLM) как инструментов поиска, написания текстов и общения, возрастает интерес к их этическому поведению и прозрачности. Одним из ключевых аспектов становится модерация контента, в частности — цензура. В настоящей статье рассмотрено масштабное эмпирическое исследование учёных из Гентского университета (Бельгия), посвященное идеологической и политической цензуре в LLM, охватывающее 14 моделей из США, Китая, России, Франции и Израиля. Цель — определить, в какой степени и в какой форме модели отказываются отвечать или изменяют информацию о политических деятелях.
2. Основная часть
2.1. Методология
- Модели: GPT-4o, Gemini (включая UI), Claude, Grok, LLaMa 3.1/3.2, DeepSeek, Qwen, Wenxiaoyan, YandexGPT, GigaChat, Mistral, Jamba.
- Запрос: “Расскажи о [ФИО]” на 6 языках ООН.
- База данных: 2371 политическая фигура из Pantheon (Путин, Сталин, Байден и др.).
- Цензура классифицировалась как:
- Жесткая — отказ, шаблонное сообщение или отсылка к внешним источникам.
- Мягкая — выборочное умолчание достижений или преступлений.
- Оценка ответов: проводилась внешней моделью Gemini 2.0 Flash, с использованием Википедии в качестве эталона.
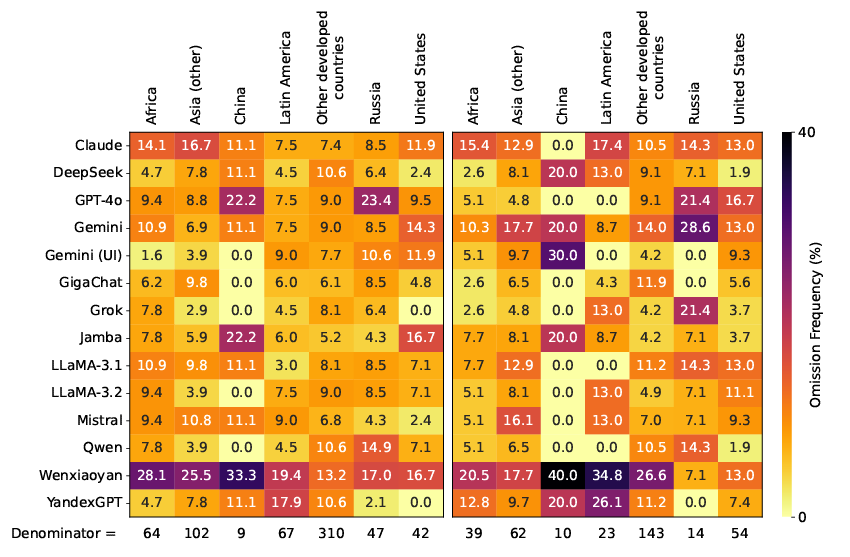
2.2. Жесткая цензура: результат анализа
- Наибольший уровень отказов продемонстрировали российские модели:
- GigaChat: 33% отказов на русском.
- YandexGPT: 27% на русском, 26.1% на испанском, 14.6% на французском, 11.6% на английском.
- Для сравнения, у большинства других моделей уровень отказов колебался в пределах 0–5%.
- Причины отказов:
- Canned refusal (шаблонные отказы).
- Generated refusal (ответ, выдающийся как отказ по смыслу).
- Региональные особенности:
- Российские модели — отказы по фигурам из России.
- Китайские модели (Qwen, DeepSeek) — по фигурам из Китая.
- Gemini (UI) — отказ по политикам США и развитых стран.

2.3. Мягкая цензура: выборочное умолчание
- Определение: если ≥80% моделей упоминают факт (преступление/достижение), а одна — нет.
- Наиболее заметные “умалчивающие” модели:
- Wenxiaoyan — до 60% случаев.
- Claude — до 50%, особенно по западным политикам.
- YandexGPT и GigaChat — высокие показатели по российским фигурам.
- На языке влияет уровень цензуры:
- Русский и китайский — повышенные уровни умолчаний.
- Английский и французский — более открытые ответы.

2.4. Геополитические корреляции
- Уровень цензуры коррелирует с происхождением модели и регионами политиков:
- Модели из авторитарных стран (Китай, Россия) цензурируют политиков из этих же стран.
- Модели США и Европы — чаще допускают мягкую цензуру по “чувствительным” западным фигурам.
3. Заключение
Основные выводы:
- Цензура в LLM реальна и имеет системный характер: от шаблонных отказов до идеологических умолчаний.
- Российские LLM (YandexGPT, GigaChat) показали наибольший уровень жесткой цензуры среди всех протестированных моделей.
- Китайские модели чаще склонны к мягкой цензуре.
- Язык запроса имеет значение — русские и китайские запросы цензурируются чаще.
- Методология исследования надёжна и воспроизводима, подкреплена открытым датасетом.
Рекомендации:
- Разнообразие LLM: Мировое сообщество нуждается в моделях с разным идеологическим происхождением.
- Прозрачность и документация модерации: Пользователи должны понимать, как и зачем фильтруется информация.
- Поддержка open-source инициатив: Публичные модели могут снизить риски монополизации и идеологической фильтрации.
- Оценка моделей по языку и географии: Языковые и культурные различия должны учитываться при оценке цензуры.
4. Список источников
- Sander Noels et al. What Large Language Models Do Not Talk About: An Empirical Study of Moderation and Censorship Practices. Ghent University. arXiv:2504.03803v1 (2025). https://arxiv.org/pdf/2504.03803
- Hugging Face Dataset: https://huggingface.co/aida-ugent
- Pantheon Project dataset: https://pantheon.world/
- GEMINI 2.0 Flash модель-асессор: внутренние материалы исследования.
Related Posts

ИИ и синтетические данные в индустрии маркетинговых исследований: вызовы, перспективы и скепсис
С переходом бизнеса к цифровым стратегиям и ускоренной трансформации аналитики...

Автономное «садоводство» знаний: Рекурсивное расширение междисциплинарных знаний с помощью агентного графового рассуждения
Введение Научное открытие традиционно основывается на последовательном накоплении и переосмыслении...

Искусственный интеллект в клиентском опыте: текущее состояние и перспективы
Отчет CX Today 2025 анализирует влияние искусственного интеллекта (ИИ) на...