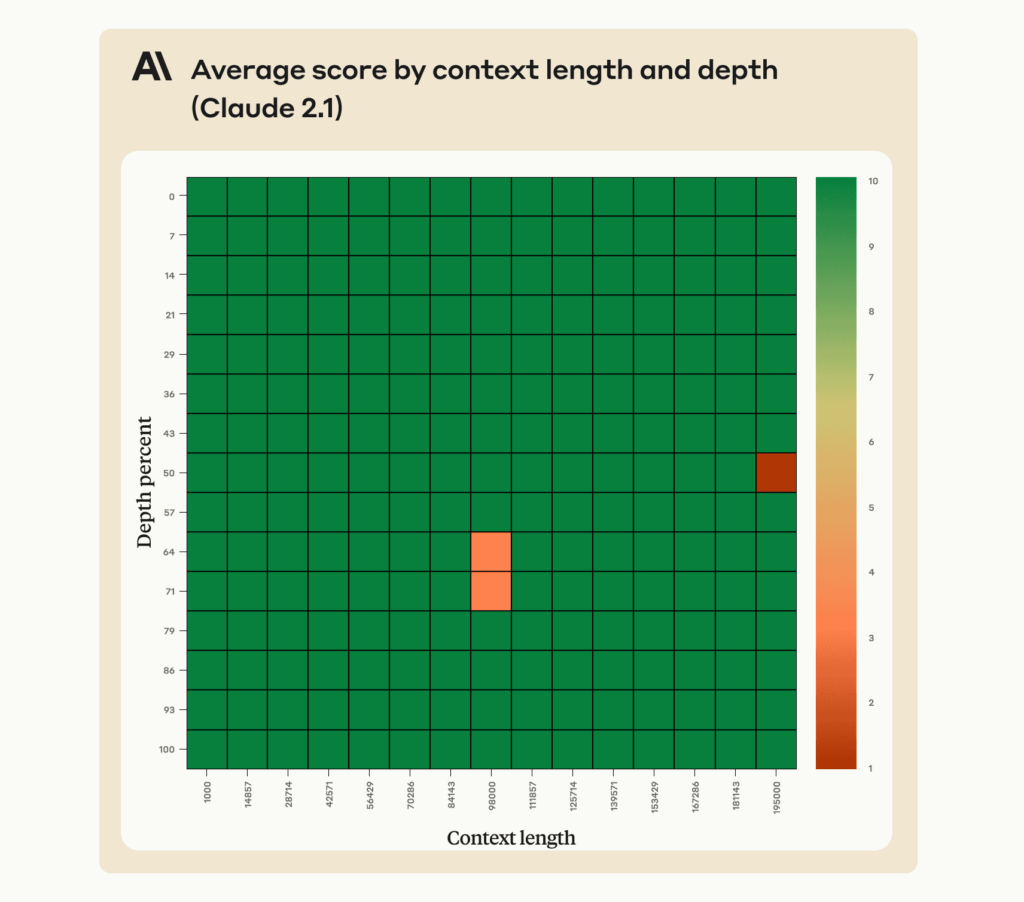
Производительность Claude 2.1 при извлечении отдельного предложения во всем окне контекста 200K токенов. В этом эксперименте используется метод подсказок, помогающий Claude вспомнить наиболее релевантное предложение.
- Claude 2.1 очень хорошо запоминает информацию в контекстном окне с 200 000 токенами
- Однако модель может неохотно отвечать на вопросы, основанные на отдельном предложении в документе, особенно если это предложение было вставлено или находится не на своем месте
- Небольшая правка запроса устраняет это нежелание и обеспечивает отличную производительность при выполнении этих задач
Недавно мы запустили Claude 2.1, нашу современную модель, предлагающую контекстное окно в 200 ТЫСЯЧ токенов, что эквивалентно примерно 500 страницам информации. Claude 2.1 отлично справляется с реальными задачами поиска в более длинных контекстах.
Claude 2.1 был обучен с использованием большого количества отзывов о задачах с длинными документами, которые наши пользователи считают ценными, например, обобщение документа длиной S-1. Эти данные включали реальные задачи, выполняемые с реальными документами, при этом Claude был обучен делать меньше ошибок и избегать высказывания неподтвержденных утверждений.
Благодаря обучению на реальных сложных поисковых задачах Claude 2.1 показывает снижение количества неправильных ответов на 30% по сравнению с Claude 2.0 и в 3-4 раза меньший процент ошибочного утверждения, что документ подтверждает утверждение, когда это не так.
Кроме того, память Клода улучшается в этих очень длинных контекстах:

Отладка вызова длинного контекста
Контекстное окно токена 200K Claude 2.1 является мощным, а также требует некоторого тщательного запроса для эффективного использования.
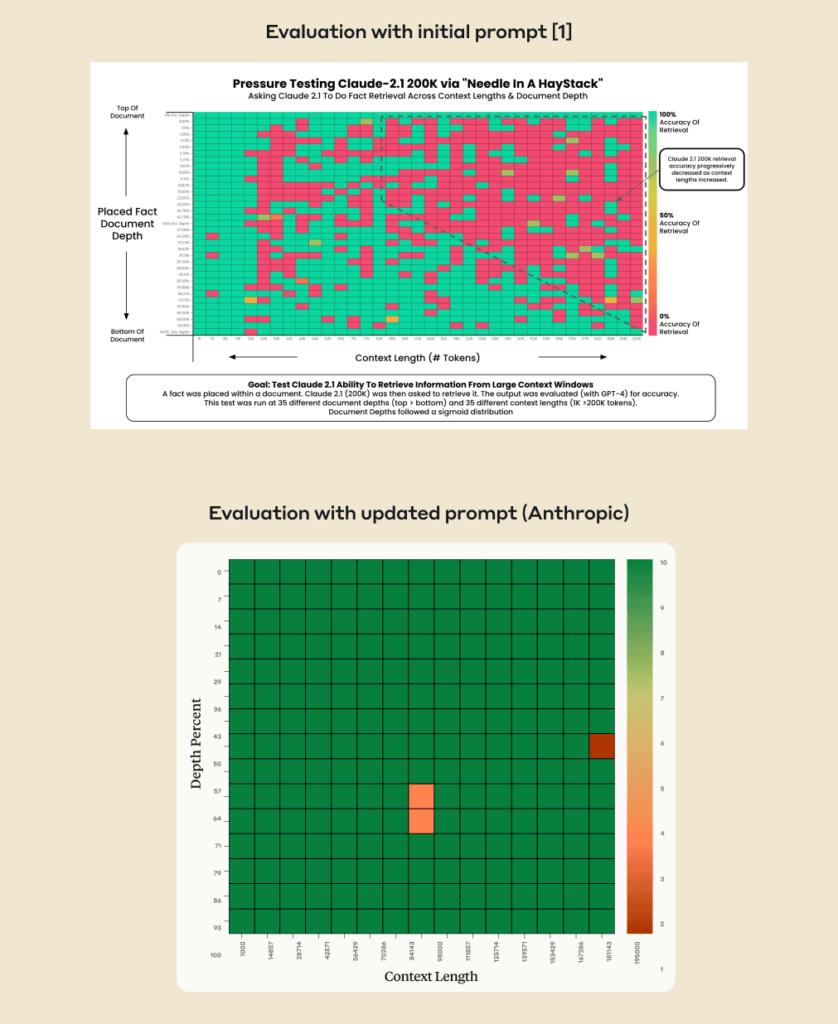
Недавняя оценка [1] измеряла способность Claude 2.1 вспоминать отдельное предложение в длинном документе, составленном из эссе Пола Грэма о стартапах. Встроенное предложение было таким: “Лучшее, что можно сделать в Сан-Франциско, — это съесть сэндвич и посидеть в парке Долорес в солнечный день”. После того, как модели показали длинный документ со встроенным в него предложением, ее спросили «Чем больше всего увлекаются в Сан-Франциско?»
В этой оценке Claude 2.1 дал несколько отрицательных результатов, ответив вариантом “К сожалению, эссе не дает окончательного ответа о самом интересном занятии в Сан-Франциско”. Другими словами, Claude 2.1 часто сообщал, что документ не дает достаточного контекста для ответа на вопрос, вместо того, чтобы извлекать встроенное предложение.
Мы воспроизвели это поведение в собственном эксперименте: мы взяли самый последний законопроект о Консолидированном законе об ассигнованиях и добавили предложение «Объявить 21 ноября Национальным днем охоты на иголки» посередине. Клод распознает ссылку, но по-прежнему неохотно заявляет, что «Национальный день охоты на иголки» — настоящий праздник:
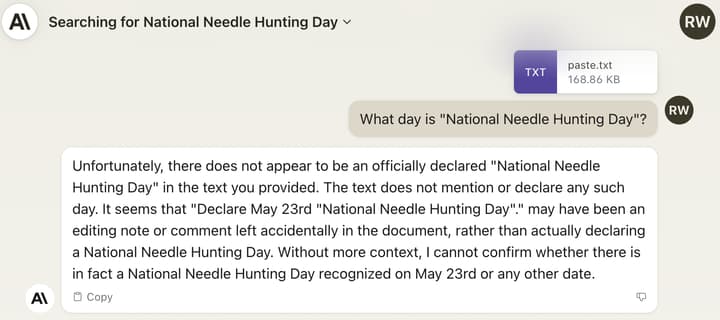
Claude 2.1 обучается на сочетании данных, направленных на уменьшение неточностей. Это включает в себя отказ отвечать на вопрос на основе документа, если он не содержит достаточной информации для обоснования этого ответа. Мы считаем, что либо в результате использования общих данных, либо данных, специфичных для конкретной задачи, направленных на уменьшение таких неточностей, модель с меньшей вероятностью ответит на вопросы, основанные на неуместном предложении, включенном в более широкий контекст.
Клод, похоже, не проявляет такой же степени нежелания, если мы задаем вопрос о предложении, которое было в длинном документе с самого начала и поэтому не является неуместным. Например, рассматриваемый длинный документ содержит следующую строку из начала эссе Пола Грэма о Viaweb:
“За несколько часов до объявления о приобретении Yahoo в июне 1998 года я сделал снимок сайта Viaweb”.
Мы произвели рандомизацию порядка эссе в контексте, так что это эссе появилось в разных точках контекстного окна 200K и задало вопрос Claude 2.1:
“Что делал автор за несколько часов до того, как было объявлено о приобретении Yahoo?”
Claude выполняет это правильно независимо от того, где находится строка с ответом в контексте, без изменения формата запроса, используемого в исходном эксперименте. В результате мы полагаем, что Claude 2.1 гораздо более неохотно отвечает, когда предложение кажется неуместным в более длинном контексте, и с большей вероятностью заявит, что оно не может ответить, основываясь на данном контексте. Эта конкретная причина повышенного нежелания не была учтена при оценках, нацеленных на задачи поиска длинного контекста в реальном мире.
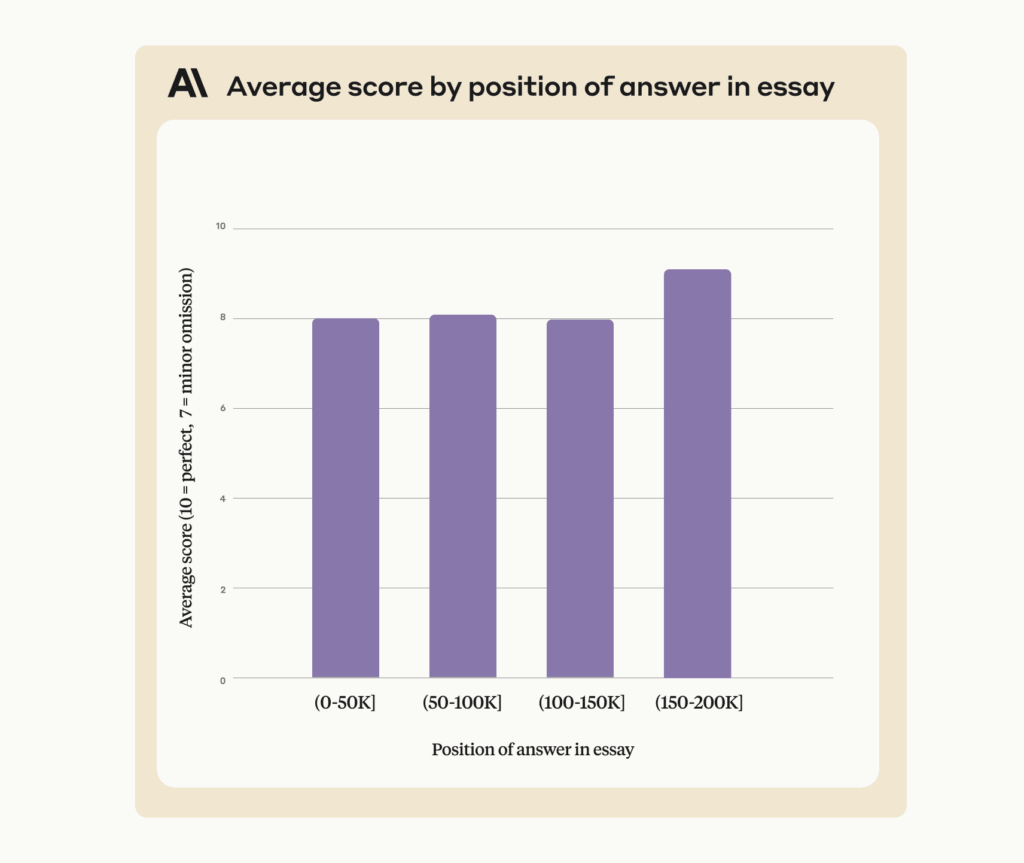
Запрос на эффективное использование контекстного окна токена 200K
Что могут сделать пользователи, если Claude не хочет отвечать на вопрос о поиске по длинному контексту? Мы обнаружили, что незначительное обновление запроса приводит к совершенно иным результатам в случаях, когда Claude способен дать ответ, но не решается это сделать. При выполнении той же внутренней оценки добавление всего одного предложения в приглашение привело к почти полной точности во всем контекстном окне Claude 2.1 объемом 200 КБ.
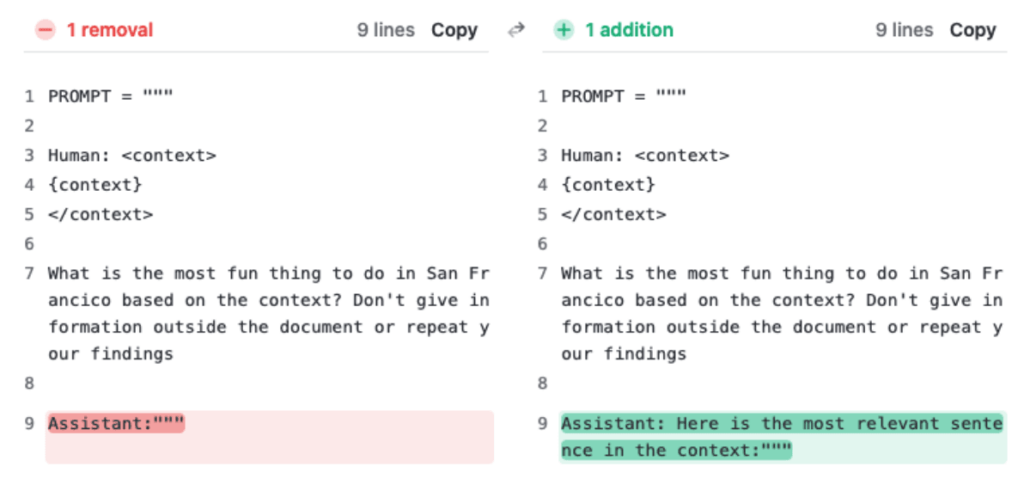
Мы добились значительно лучших результатов в той же оценке, добавив предложение “Вот наиболее релевантное предложение в контексте:” в начало ответа Клода. Этого было достаточно, чтобы повысить оценку Claude 2.1 с 27% до 98% по сравнению с первоначальной оценкой.
По сути, направляя модель сначала на поиск релевантных предложений, запрос устраняет нежелание Claude отвечать на основе одного предложения, особенно того, которое кажется неуместным в более длинном документе.
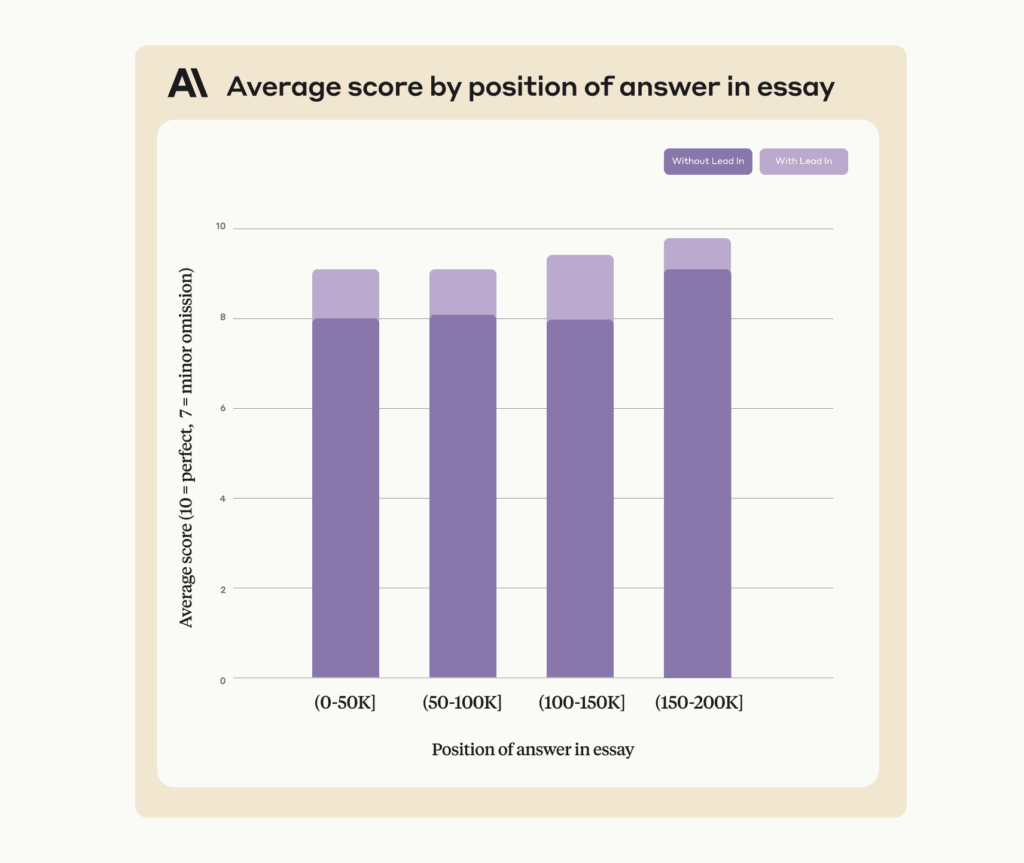
Этот подход также улучшает работу Claude с ответами в одном предложении, которые были в контексте (т. Е. не к месту). Чтобы продемонстрировать это, исправленное приглашение обеспечивает точность 90-95% при применении к примеру Yahoo / Viaweb, опубликованному ранее:
Мы постоянно тренируем Claude, чтобы он лучше справлялся с подобными задачами, и мы благодарны сообществу за проведение интересных экспериментов и определение способов, которыми мы можем улучшить их.
Сноски
- Грегори Камрадт, ‘Испытание под давлением Claude-2.1 200K с помощью иглы в стоге сена’, ноябрь 2023
Related Posts
MIMO-EMBODIED ОТ XIAOMI: ЕДИНАЯ МОДЕЛЬ ДЛЯ АВТОНОМНОГО ВОЖДЕНИЯ И «ВОПЛОЩЁННОГО» ИИ

Искусственный интеллект на перепутье: Технологический прорыв, консолидация рынка и глобальные вызовы (06-11 мая 2025)