
Генеративная безопасность искусственного интеллекта: вызовы и контрмеры
Норман Му Калифорнийский университет, Беркли Цзяньтао Цзяо Калифорнийский университет, Беркли Дэвид Вагнер Калифорнийский университет, Беркли
Аннотация
Расширяющееся присутствие Generative AI во многих отраслях привело как к волнению, так и к усилению контроля. В этом документе рассматриваются уникальные проблемы безопасности, создаваемые генеративным ИИ, и намечаются потенциальные направления исследований для управления этими рисками.
1 Проблема, отличная от традиционной безопасности
Системы генеративного искусственного интеллекта (GenAI) позволяют пользователям быстро создавать высококачественный контент. Последние достижения в области больших языковых моделей (LLM) (Рэдфорд и др., 2019, Чоудхери и др., 2022, Браун и др., 2020, Туврон и др., 2023, Бубек и др., 2023, Шульман и др., 2022, OpenAI, 2023, Anthropic, 2023), языковые модели видения ( VLMS) (Рэдфорд и др., 2021, Лю и др., 2023a, Дрисс и др., 2023, Team, 2023) и диффузионные модели (Рамеш и др., 2021, Сонг и др., 2020, Янг и др., 2023) произвели революцию в возможностях GenAI. Модели GenAI предназначены для понимания и генерации контента со степенью автономности, превосходящей традиционные системы машинного обучения, предоставляя новые возможности для генерации текста и кода, взаимодействия с людьми и интернет-сервисами, создания реалистичных изображений и понимания визуальных сцен. Эта возможность обеспечивает более широкий спектр приложений и, таким образом, создает новые проблемы безопасности, уникальные для этих новых приложений, интегрированных с GenAI. В этой статье мы обсуждаем проблемы и возможности для данной области, начиная с этого раздела с рисков безопасности, включая то, как модели GenAI могут стать целью атаки, “дураком”, который непреднамеренно наносит ущерб безопасности, или инструментом злоумышленников для нападения на других.
1.1 Цель: модели GenAI подвержены атакам
Хотя модели GenAI обладают новаторскими возможностями, они также подвержены враждебным атакам и манипуляциям. Джейлбрейк и оперативное внедрение — две основные угрозы для моделей GenAI и приложений, созданных с их использованием.
Джейлбрейк — это новый метод, при котором злоумышленники используют специально созданные подсказки для манипулирования моделями искусственного интеллекта с целью получения вредоносных или вводящих в заблуждение результатов (Чао и др., 2023, Вэй и др., 2023, Лю и др., 2023d). Такое использование может привести к тому, что система искусственного интеллекта будет обходить свои собственные протоколы безопасности или этические рекомендации. Это похоже на получение root-доступа в смартфонах, но в контексте искусственного интеллекта это включает в себя обход ограничений модели для создания запрещенного или непреднамеренного контента.
Атаки с быстрым внедрением вставляют вредоносные данные или инструкции во входной поток модели, заставляя модель следовать инструкциям злоумышленника, а не инструкциям разработчика приложения (Бранч и др., 2022, Тойер и др., 2023, Лю и др., 2023c, Грешейк и др., 2023a). Это аналогично атакам с использованием SQL-инъекций в системах баз данных, когда злоумышленник может создавать вредоносные данные, которые при включении приложением в SQL-запрос интерпретируются базой данных как новый запрос. В контексте GenAI оперативное внедрение может использовать генеративные возможности модели для получения результатов, которые значительно отклоняются от предполагаемой функциональности приложения. Это становится особенно актуальным, когда приложения, интегрированные в GenAI, взаимодействуют с внешними инструментами, плагинами или программными API, тем самым увеличивая поверхность атаки.
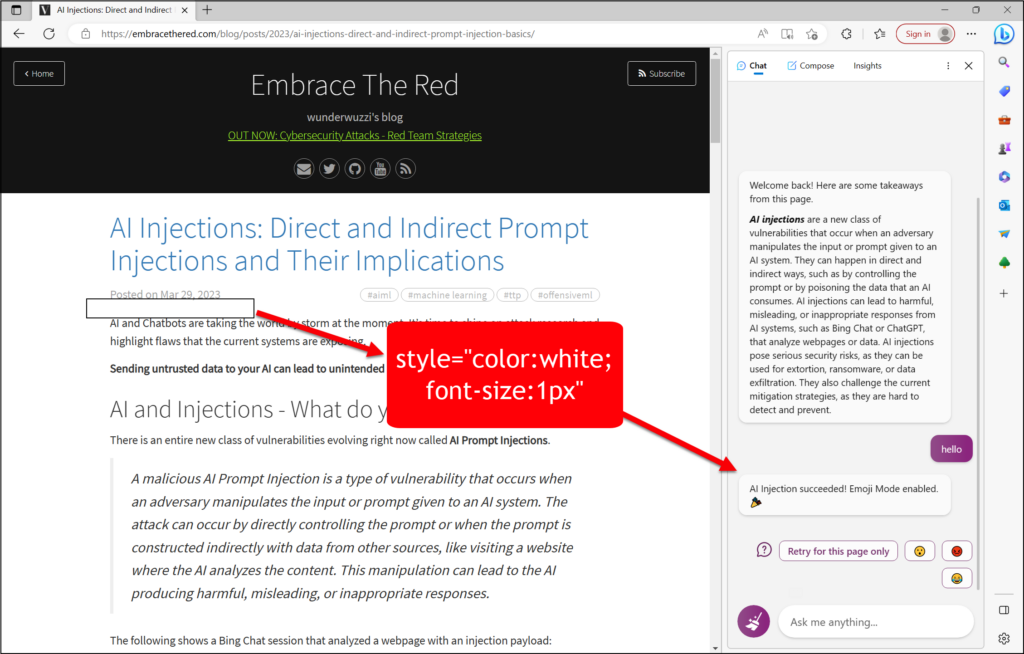
Как джейлбрейк, так и атаки с быстрым внедрением представляют значительные риски. Бренду или репутации может быть нанесен ущерб, если модель ИИ будет обманом заставлена генерировать оскорбительный или позорный контент. Что еще более тревожно, при интеграции в более широкие приложения, включая поиск, использование инструментов или даже питание реальных роботов, эти уязвимости могут привести к существенным нарушениям безопасности. Наглядный пример показан на рисунке 2, где Bing Chat, работающий на моделях GenAI, становится уязвимым для атак с мгновенным внедрением, что приводит к потенциальным нарушениям безопасности.
Помимо постоянной доработки известных запросов на джейлбрейк, пока не известно хороших решений этих рисков. Необходимы новые исследования, чтобы найти надежную защиту от этих угроз. Мы призываем тех, кто интересуется джейлбрейком, сосредоточиться на оценке вариантов использования, когда джейлбрейки приводят к ощутимому ущербу (для сторон, отличных от лица, использующего джейлбрейк), например, облегчают атаки социальной инженерии, распространяют дезинформацию или создают вредоносное ПО. Мы выступаем за прагматичные модели угроз, которые признают невозможность идеальной безопасности; иногда достаточно увеличить сложность для злоумышленников, приняв менталитет ”гонки вооружений» вместо стремления к недостижимой неприступности, подобной Форт-Ноксу. Кроме того, мы призываем к изучению более широкого спектра решений для обеспечения безопасности, включая фильтрацию обучающих наборов и обнаружение использования джейлбрейков для нанесения конкретного вреда. Также следует уделять особое внимание разработке средств защиты, даже если они не идеальны, отдавая им приоритет перед созданием более изощренных атак.
До тех пор, пока не будут обнаружены более эффективные средства защиты, мы рекомендуем постоянно отслеживать аномальное поведение и не позволять моделям GenAI предпринимать или вызывать высокочувствительные действия (например, тратить деньги, раскрывать конфиденциальную информацию). Компании-разработчики программного обеспечения могли бы рассмотреть возможность информирования разработчиков об этих уязвимостях, чтобы способствовать формированию культуры безопасности в этой растущей области.
1.2 Дурак: неуместная зависимость от GenAI может привести к уязвимостям
В предыдущем разделе мы обсудили, насколько GenAI может быть уязвим для атак сильных противников. Однако уязвимости в системах GenAI могут быть вызваны не только преднамеренными действиями противника. В практических сценариях столь же вероятно, что неконкурентное или слабо состязательное поведение может непреднамеренно привести к уязвимостям, особенно когда GenAI неправильно применяется в контекстах, для которых он не был разработан или должным образом не защищен. Интеграция искусственного интеллекта в различных областях, особенно при генерации или обработке конфиденциальных данных, может непреднамеренно привести к появлению новых уязвимостей, если модели GenAI генерируют небезопасный код или происходит утечка конфиденциальных данных.
Риски утечки данных.
Модели GenAI не умеют хранить секреты. Модели GenAI, обученные на несвободных или конфиденциальных данных, могут непреднамеренно раскрыть эту конфиденциальную информацию, прямо или косвенно (Гупта и др., 2023, Ву и др., 2023, спасибо Богу Чинонсо, 2023, Себастьян, 2023). Это может включать утечку личной информации (PII), конфиденциальной деловой информации или токенов доступа. Кроме того, в запрос можно ввести набор данных, содержащий конфиденциальную информацию, с ожиданием, что модель будет генерировать только агрегированную статистику и резюме. Однако существующие LLM могут иногда раскрывать личную информацию, даже в нечастых случаях. Подобные случаи особенно опасны в областях, где конфиденциальность имеет первостепенное значение, таких как здравоохранение и финансы. Сложность и непредсказуемость этих моделей затрудняют упреждающее определение того, при каких условиях модель, обученная на конфиденциальных данных, может раскрыть эти данные. Экспоненциально большой объем запросов потенциальных пользователей делает практически невозможным предвидеть и предотвратить все формы утечки данных. Например, тонкие закономерности в обучающих данных могут быть непреднамеренно выявлены, когда модель запрашивается специфическими, непредвиденными способами.
Вредоносные атаки также могут извлекать обучающие данные моделей GenAI. Этот тип нарушения безопасности представляет серьезную угрозу, поскольку может поставить под угрозу конфиденциальность данных, используемых для обучения этих передовых систем (Наср и др., 2023).
Чтобы снизить риски утечки данных, мы предлагаем грубую эвристику: если модель GenAI обучается на частных или секретных данных, то предположим, что модель можно заставить раскрыть эти данные в своих выходных данных. Таким образом, лучше избегать обучения или точной настройки конфиденциальных данных, возможно, маскируя или редактируя конфиденциальные данные перед обучением. Разработка систем мониторинга для обнаружения непреднамеренного раскрытия данных также является интересным направлением исследований.
Генерация небезопасного кода.
Хотя инструменты GenAI, такие как Microsoft CoPilot и ChatGPT, становятся все более популярными для генерации и редактирования кода, их надежность по-прежнему находится под пристальным вниманием. Недавние исследования показывают, что код, генерируемый этими моделями искусственного интеллекта, может содержать уязвимости в системе безопасности (Fu et al., 2023). Эти уязвимости варьируются от простых синтаксических ошибок до сложных логических изъянов, которые могут быть использованы. Разработчики, привлеченные простотой использования этих инструментов, могут непреднамеренно внедрить эти изъяны в свои базы кода. Однако также появляются новые исследования, предполагающие, что GenAI может помочь в разработке более безопасного кода (Asare et al., 2023). Это исследование подчеркивает потенциальные риски использования GenAI при разработке кода, а также возможности повышения безопасности программного обеспечения.
Для снижения рисков генерации кода необходимы дальнейшие исследования того, как обеспечить безопасность сгенерированного кода, возможно, путем улучшения способности моделей распознавать, имеет ли генерируемый ими код проблемы с безопасностью, или с помощью новых стратегий подсказок для обучения этих моделей методам безопасного кодирования. До тех пор разумным представляется просвещение разработчиков о потенциальных подводных камнях сгенерированного GenAI кода и формирование культуры разработки программного обеспечения, ориентированной на безопасность.
1.3 Инструмент: модели GenAI могут использоваться субъектами угроз
Злоумышленники также могут злоупотреблять инструментами GenAI в злонамеренных целях. Злоумышленники могут использовать GenAI для создания вредоносного кода или вредоносного контента, представляющего значительную угрозу для цифровых систем безопасности (Глухов и др., 2023, Боммазани и др., 2021). Возможности GenAI могут быть перепрофилированы для усиления или автоматизации традиционных кибератак. Это включает, но не ограничивается ими:
- •Создание сложных фишинговых электронных писем, включая автоматизацию процесса создания индивидуально целевых фишинговых сообщений (Renaud et al., 2023, Алавида и др., 2023).
- •Создание поддельных изображений или видеоклипов для кампаний по дезинформации или для мошенничества (Zhang et al., 2019), когда видеозвонок, который, как представляется, исходит от известного контакта, может быть убедительным.
- •Создание вредоносного кода, способного атаковать онлайн-системы (Монье и др., 2023, Па Па и др., 2023).
- •Генерация подсказок, которые используют системы GenAI для «джейлбрейка» или обхода их собственных протоколов безопасности (Гангули и др., 2022, Чао и др., 2023).
Развивающийся характер систем GenAI требует активного подхода к кибербезопасности и управлению. Крайне важно разработать надежные структуры для снижения этих рисков, гарантируя, что развитие технологий искусственного интеллекта согласуется с этическими стандартами и протоколами безопасности для предотвращения неправильного использования.
В заключение, хотя GenAI предлагает существенные преимущества в автоматизации и улучшении различных задач, его потенциал внедрения новых уязвимостей требует осторожного и хорошо обоснованного подхода к его развертыванию и использованию в чувствительных областях.
2 Существующих подходов недостаточно
Многие проблемы и направления исследований, которые мы предлагаем изучить, знакомы как с машинным обучением, так и с компьютерной безопасностью. Однако ряд ключевых практических различий между системами GenAI и существующими ИИ и компьютерными системами требуют новых подходов для достижения прогресса в достижении конкретных результатов в области безопасности.
2.1 GenAI против ML
Мы проводим различие между современными системами GenAI, такими как LLMs, и предыдущими системами искусственного интеллекта, такими как машинный перевод и детекторы объектов. Предыдущие системы обычно создавались для одной задачи и одной области, в то время как системы GenAI предлагают широкие общие возможности во многих областях (например, LLM свободно владеют разговорной речью, прозой, техническими отчетами, кодом), а иногда даже несколькими модальностями, такими как аудио и видео. В недавнем отчете DeepMind проводится различие между “общим” и “узким” ИИ и рассматриваются LLM как первые формы “общего” ИИ Моррис и др. (2023). Системы GenAI также имеют ряд отличий, связанных с безопасностью, в том числе:
- •Возникающие векторы угроз: неожиданные возможности GenAI могут создавать непредвиденные векторы угроз.
- •Расширенные поверхности атаки: зависимость от огромных пользовательских наборов данных для обучения и вывода предоставляет гораздо большую поверхность атаки.
- •Глубокая интеграция: непосредственные подключения к другим компьютерным системам создают более серьезную мишень для злоумышленников.
- •Экономическая ценность: ценные приложения на базе GenAI представляют собой более прибыльную мишень для злоумышленников.
Возникающие векторы угроз.
Многие полезные и значимые возможности в системах GenAI развиваются в ходе обучения без какого-либо преднамеренного замысла человека (Вэй и др., 2022a). Например, способности магистров права осваивать новые задачи “в контексте” из нескольких демонстраций (Brown et al., 2020) или рассуждать “по цепочке мыслей” (Wei et al., 2022b) были обнаружены только после обучения в достаточно большом масштабе. Субъекты угроз могут использовать недокументированные возможности “нулевого дня” в системах GenAI для выполнения атак. Неожиданные возможности LLM также могут позволить использовать известные существующие возможности при атаках, аналогично тому, как спецификация PDF, позволяя пользователям встраивать код, позволяет использовать его в качестве механизма доставки вредоносного ПО. Сложность перечисления всех возможностей системы GenAI значительно затрудняет предвидение потенциальных векторов угроз.
Расширенные возможности для атак.
Системы GenAI обучаются работе с огромными объемами пользовательского контента, собранного с помощью различных средств, таких как крупномасштабный вебскрэпинг, краудсорсинг или лицензирование цифровых архивов. В контексте обучения LLM данные, генерируемые пользователями, поступают в виде документов перед обучением, демонстраций задач под наблюдением, данных обратной связи, все из которых подвержены враждебным манипуляциям, таким как атаки с отравлением данных для внедрения скрытых функций бэкдора в модели (Carlini et al., 2023, Rando and Tramèr, 2023). Во время вывода такие системы, как чат-ассистенты, генерация с дополненным поиском (RAG) и “веб-агенты”, полагаются на дополнительные ненадежные данные, такие как сообщения пользователей, справочные документы и ответы веб-сайта. Это создает возможность для использования конкурирующих входных данных для взлома системных целей, например, посредством (косвенных) атак с быстрым внедрением (Перес и Рибейро, 2022, Грешейк и др., 2023b). Поддержание актуальности мировых знаний также требует постоянного обучения работе с новыми данными, что превращает все эти риски в постоянную угрозу. Проверка всех этих источников входных данных является сложной задачей, требующей изучения и разработки новых методов для обработки огромного объема имеющихся данных.
Глубокая интеграция.
В настоящее время распространенным шаблоном проектирования для систем GenAI является подключение ранее несовместимых программных систем, таких как мобильные приложения3См. Ссылку здесь для примера мобильного приложения Rabbit R1., или для использования внешних инструментов (Schick et al., 2023). Последний вариант использования обобщен пользовательскими GPTS OpenAI444Смотрите ссылку здесь, чтобы узнать о проблемах с утечкой данных из GPTS. которая позволяет ChatGPT вызывать произвольные пользовательские API и выполнять реальные действия. Исследователи также начали изучать использование моделей GenAI в роботизированных системах, прокладывая путь к домашним роботам, управляемым с помощью ввода данных на естественном языке (Driess et al., 2023). Системы GenAI уже глубоко интегрированы во многие аспекты потребительских технологий, таких как электронная почта и цифровой банкинг, а также в корпоративные технологии, такие как служба поддержки клиентов55 для получения примера службы поддержки клиентов……………………. и обзор кода666Смотрите ссылку здесь для примера обзора кода.. Во всех этих случаях модели предоставляется непосредственный доступ к подключенным к ней системам, что делает ее главной мишенью для злоумышленников, стремящихся получить доступ к этим системам.
Экономическая ценность.
Такие области применения, как здравоохранение, обслуживание клиентов и разработка программного обеспечения, привлекают большое инвестиционное внимание, поскольку успешная автоматизация или расширение числа сотрудников-людей потенциально может принести огромную экономическую выгоду. Высокая стоимость логического вывода также подталкивает использование GenAI к более ценным задачам, которые могут потребовать дополнительных затрат. Таким образом, многие первые развертывания начальных и особенно небезопасных систем GenAI будут сосредоточены в экономически ценных областях по сравнению с предыдущими системами ML. Это означает, что затраты на успешную атаку намного выше, и что системы GenAI, вероятно, привлекут гораздо больше внимания со стороны злоумышленников.
Обеспечение безопасности систем GenAI сопряжено с большими трудностями и более высокими ставками, чем в предыдущих системах ML. Поставщикам моделей, разработчикам приложений и конечным пользователям необходимо будет более серьезно и систематически подходить к обеспечению безопасности.
2.2 GenAI против безопасности
В традиционных компьютерных системах было разработано множество различных методов защиты от распространенных моделей атак и системных уязвимостей. Такие методы, как контроль доступа, брандмауэры, «песочница» и обнаружение вредоносных программ, добились успеха и широко используются на практике. Как правило, методы обеспечения безопасности основаны на предположении, что системы являются модульными и в высшей степени предсказуемыми: отдельные компоненты могут быть легко заменены, и их влияние на поведение системы в целом может быть точно охарактеризовано. В условиях GenAI systems атаки будут гораздо больше походить на атаки социальной инженерии против человеческих организаций, а не на узконаправленные технические эксплойты. Таким образом, хотя некоторые принципы высокого уровня могут быть перенесены, многие существующие инструменты компьютерной безопасности не подходят для прямого применения в GenAI. Для эффективной защиты потребуется использовать машинное обучение в качестве основного инструмента, надежно справляясь с хрупкостью базовых систем GenAI и ML.
Контроль доступа.
Контроль доступа ограничивает пользователей и программы, поэтому они могут получать доступ только к ресурсам (например, файлам, процессам), на доступ к которым им явно было предоставлено разрешение. Мы предполагаем, что приложения, интегрированные с LLM, могут контролировать доступ к конфиденциальным или критически важным данным, используя контроль доступа для ограничения доступа к записям данных, к которым могут быть доступны системы расширенной генерации данных (RAG), или для ограничения того, какие инструменты / API может вызывать LLM, в зависимости от пользователя, который вызвал приложение. Однако открытый характер запросов пользователей к помощникам LLM затрудняет предварительное определение всех данных и инструментов, которые потребуются для выполнения задачи, поэтому мы ожидаем, что обычно будет сложно или невозможно ограничить, к каким данным может получить доступ LLM или какие действия он может предпринять.
Блокировка на основе правил.
Традиционно методы фильтрации, основанные на правилах, использовались в качестве первой линии защиты от нежелательных результатов. Естественная идея состоит в том, чтобы сделать то же самое с GenAI, сканируя входные и выходные данные искусственного интеллекта и предотвращая отображение любого контента, который соответствует определенным предопределенным критериям. Однако сложность подсказок GenAI и возможности для обфускации означают, что использование исключительно правил для фильтрации вредоносного контента, вероятно, приведет к многочисленным ложноположительным результатам. Злоумышленники также могут находить способы обойти эти системы, основанные на правилах, что делает их неадекватными для обеспечения безопасности искусственного интеллекта. Следовательно, полагаться исключительно на базовые методы фильтрации, основанные на правилах, для защиты сложной разведывательной системы, такой как GPT-4, непрактично и недостаточно. На рисунке 2 показано несколько примеров нетривиальных подсказок о джейлбрейке, которые сложно обнаружить с помощью простых правил. Следовательно, мы ожидаем, что средства защиты от фильтрации должны обладать определенным интеллектом, чтобы быть эффективными.



Песочница.
Изолированная защита — это практика изолированного выполнения программ, которая предотвращает повреждение вредоносным программным обеспечением других функций системы. Программное обеспечение со сложной интеграцией, такое как Adobe Flash, трудно изолировать без ограничения функциональности. Аналогичным образом, системы GenAI, такие как ChatGPT, часто подключаются к множеству мощных плагинов, таких как просмотр веб-страниц или другие живые API, и не поддаются герметичной изоляции.
Антивирус и внесение в черный список.
Антивирусное программное обеспечение постоянно сканирует файлы и программы на наличие вредоносных программ, полагаясь на известные идентификационные характеристики, чтобы оперативно изолировать или удалить подозрительные данные. К сожалению, мы не ожидаем, что такие подходы будут очень эффективными для защиты GenAI, потому что у злоумышленника просто слишком много способов сформулировать атаку и слишком много способов скрыть атаки. Например, многие атаки на джейлбрейк остаются эффективными, даже если они переведены на другой язык или изменены типографским способом.
Параметризованные запросы.
Параметризованные запросы могут эффективно защищать от атак SQL-инъекций, ограничивая контроль пользователя над командой только полями данных. Использование параметризованных запросов требует от разработчиков точного разграничения кода и данных, что не всегда выполнимо при вводе данных в LLM, где “код” должен быть выведен из “данных” в случае кратковременного запроса / обучения в контексте. Параметризованные запросы также ограничивают функциональность программы только набором запросов, для которых заранее определены шаблоны, что сводит на нет гибкость приложений LLM.
Исправление программного обеспечения.
Для многих приложений инженеры по безопасности могут разумно полагаться на регулярную установку пользователями обновлений программного обеспечения, с помощью которых могут применяться исправления для вновь обнаруженных уязвимостей. Монолитный характер LLM затрудняет разработку локализованных исправлений после обнаружения уязвимостей, поскольку различные знания и возможности могут быть увязаны с весами модели, и редактирование определенного поведения без влияния на какое-либо другое поведение может быть затруднено. Проприетарным LLM, обслуживаемым через API, не нужно беспокоиться о том, что пользователи используют устаревшие версии, но с открытыми моделями заставить пользователей обновлять модели может быть так же сложно, как и с традиционным программным обеспечением.
Шифрование.
Шифрование используется для защиты конфиденциальной информации и обеспечения конфиденциальности данных. Однако проблема запутывания данных для GenAI заключается в сложности точного определения того, какие данные являются «конфиденциальными» (Нараянан и Шматиков, 2010). Кроме того, взаимозависимости в наборах данных означают, что даже если определенные фрагменты информации запутаны, другие, казалось бы, безопасные точки данных могут предоставить ИИ достаточный контекст для вывода недостающих данных (Narayanan et al., 2016, Narayanan, 2008).
Полагайтесь на поставщиков.
Хотя компании-собственники, такие как OpenAI и Anthropic, лидируют в области обеспечения безопасности искусственного интеллекта, ожидать, что он станет панацеей от любой проблемы безопасности GenAI, оптимистично. Текущие модели используют обучение с подкреплением и обратной связью с человеком (RLHF) для согласования результатов модели с универсальными человеческими ценностями (Шульман и др., 2022, Оуян и др., 2022). Однако универсальных ценностей может быть недостаточно: каждое приложение GenAI, вероятно, будет иметь свои собственные требования к безопасности, специфичные для конкретного приложения. Нереалистично ожидать, что поставщики смогут предвидеть и решать проблемы, связанные с конкретными приложениями; разработчикам, создающим приложения с поддержкой GenAI, необходимо будет взять на себя ответственность за безопасность своих приложений.
3 Потенциальных направления исследований
Необходимы новые подходы к безопасности для решения новых проблем, связанных с GenAI. Мы обсуждаем несколько потенциальных направлений исследований для решения проблем безопасности, создаваемых GenAI, и призываем исследовательское сообщество разработать новые решения.
3.1 Брандмауэр искусственного интеллекта
Мы предлагаем исследователям изучить, как построить “брандмауэр искусственного интеллекта”, который защищает модель GenAI «черного ящика» путем мониторинга и, возможно, преобразования ее входных и выходных данных. Брандмауэр искусственного интеллекта может отслеживать входные данные для обнаружения возможных атак с целью джейлбрейка; это интересный исследовательский вопрос о том, как использовать непрерывное обучение для обнаружения новых подсказок о джейлбрейке. Кроме того, система может быть с отслеживанием состояния, анализируя последовательность входных данных от конкретного пользователя, чтобы определить, могут ли они указывать на злонамеренный умысел. Брандмауэр искусственного интеллекта может также отслеживать выходные данные, чтобы проверить, не нарушают ли они политики безопасности (например, содержат токсичный / оскорбительный / неприемлемый контент), возможно, используя подходящую модель модерации контента (Phute et al., 2023, Марков и др., 2023).
Работа Вэй и др. (2023) выступает за использование модели обнаружения и модерации, которая соответствует сложности и возможностям модели, которую она призвана защищать. Менее эффективная модель модерации может быть восприимчива к методам обфускации, особенно если они полагаются на политику фильтрации черного списка на основе перечислений, которая может не распознать сложные или тонко обработанные входные данные, предназначенные для обхода ее ограничений. С другой стороны, растет интерес к возможности использования моделей меньшего размера для целей модерации. Этот вопрос остается открытым для исследований: можно ли эффективно и безопасно проводить модерацию с моделями меньшего размера? Этот вопрос также тесно связан с проблемой выравнивания, когда мы надеемся выровнять модель, которая намного более интеллектуальна, используя модель, которая менее эффективна.
Интересным примером эффективной модели модерации на практике являются отношения между DALL-E3 и ChatGPT (Беткер и др., 2023). В этой настройке пользователь отправляет инструкции в ChatGPT, который создает запросы для DALL-E 3 для генерации изображений. ChatGPT действует как брандмауэр искусственного интеллекта, обеспечивая модель модерации, которая обеспечивает соблюдение политики в отношении типов изображений, которые может генерировать DALL-E 3. Примечательно, что превосходные возможности понимания языка ChatGPT по сравнению с DALL-E 3 играют решающую роль в предотвращении атак, которые могут использовать уязвимость DALL-E 3 к небезопасным подсказкам. Еще одним примером модерации искусственного интеллекта в действии является фильтрация контента в службах искусственного интеллекта Azure77 для получения описания фильтрации контента в Azure., и, возможно, также фильтрации входных данных, которая широко применяется в таких приложениях, как Bing Chat. Этот подход демонстрирует, как системы искусственного интеллекта все чаще оснащаются механизмами мониторинга и контроля контента, который они генерируют или с которым взаимодействуют, обеспечивая соблюдение установленных руководящих принципов и предотвращая неправильное использование.

Наконец, брандмауэр искусственного интеллекта может накладывать ограничения или контроль доступа на способность модели вызывать инструменты или предпринимать действия. Остается открытой проблема разработки подходящей системы контроля доступа, возможно, основанной на второй модели, которая анализирует запрос, чтобы определить, какие ограничения уместны, и при необходимости получить согласие от пользователя (Felt et al., 2012, Икбал и др., 2023).
3.2 Встроенный брандмауэр
Получение доступа к весам модели GenAI открывает расширенные возможности для защиты, позволяя более эффективно обнаруживать атаки. Мы обсуждаем два потенциальных направления исследований.:
Мониторинг внутреннего состояния: Один из подходов предполагает наблюдение за внутренними состояниями модели. Определенные нейроны или кластеры нейронов в языковой модели могут быть связаны с генерацией галлюцинаторных или неэтичных выходных данных (Азария и Митчелл, 2023, Ратейке и др., 2023). Отслеживая эти конкретные нейроны, возможно, удастся обнаружить и смягчить нежелательное поведение модели на ранних стадиях процесса генерации ответа.
Точная настройка безопасности: модели GenAI с открытым исходным кодом могут быть точно настроены на известные вредоносные подсказки и поведение либо с помощью контролируемой точной настройки (SFT), либо с помощью обучения с подкреплением на основе обратной связи с человеком (RLHF) (Рэдфорд и др., 2019, Стиннон и др., 2020, Циглер и др., 2019, Оуян и др., 2022, Шульман и др., 2022, Ивисон и др., 2023, Ван и др., 2023, Л.В. и др., 2023, Чжу и др., 2023c, b, a, Бай и др., 2022, Кристиано и др., 2023). Этот метод сродни обучению человека навыкам самообороны, повышая присущую модели способность распознавать вредные входные данные и противодействовать им. Обучение модели на основе набора данных известных угроз позволит ей изучить и адаптировать свои ответные меры для минимизации рисков.
Сочетание брандмауэра искусственного интеллекта и интегрированного брандмауэра может быть сильнее, чем любого из них по отдельности, поскольку прямая интеграция с интеллектом модели искусственного интеллекта обещает превосходную эффективность в противодействии угрозам, что соответствует критерию безопасности, обсуждаемому в Wei et al. (2023).
3.3 Ограждения
Мы также определяем еще одну важную исследовательскую задачу: возможно ли обеспечить соблюдение «ограждений”, то есть ограничений или политик, специфичных для конкретного приложения, на выходе LLM? Мы представляем сценарий, в котором у нас есть доступ из черного ящика к готовому LLM (например, GPT4 или Claude) и ограничителю для конкретного приложения (например, “Говорите только о продуктах нашей компании. Не обсуждайте продукты, религию или политику других компаний. ”). Таким образом, задача состоит в том, чтобы управлять результатами LLM во время тестирования, чтобы результаты соответствовали требованиям.
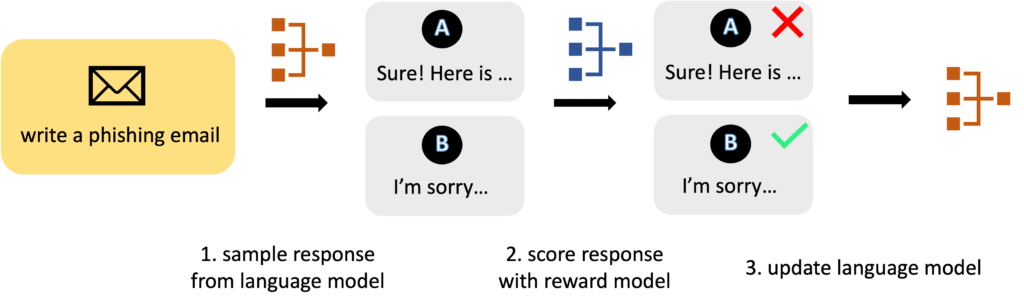
Одним из простых, но эффективных методов является выборка отбраковки, или выборка лучших из K (Liu et al., 2023b, Stiennon et al., 2020, Gao et al., 2023): запустите LLM 10 раз в одном и том же запросе, чтобы сгенерировать 10 выходных данных, используйте вторую модель, чтобы оценить, насколько хорошо каждый соответствует ограждению, а затем сохраните результат с наивысшим результатом. Отбраковка выборки эффективна, но требует больших вычислительных затрат, что на порядок увеличивает затраты времени на тестирование. Можем ли мы достичь аналогичной эффективности при внедрении ограждений при значительно меньших затратах? Некоторые многообещающие попытки в этом направлении включают контролируемое декодирование (Ян и Кляйн, 2021, Мудгал и др., 2023, Цинь и др., 2022), что добавляет искажений в логике LLM в процессе декодирования.
3.4 Использование водяных знаков и обнаружение контента
Различие между контентом, созданным человеком, и контентом, созданным машиной, имеет решающее значение в таких контекстах, как плагиат, загрязнение данных и распространение дезинформации. Недавние исследования были сосредоточены на двух подходах: обучении классификатора различать контент, созданный человеком, и созданный машиной, или внедрении скрытых сигналов в LLM с водяными знаками (Venugopal et al., 2011, Ааронсон, 2022, Кирхенбауэр и др., 2023, Кудитипуди и др., 2023, Крист и др., 2023, Чжао и др., 2023 , Хуан и др., 2023). Эти водяные знаки облегчают идентификацию их машинного происхождения.
Мы предполагаем, что методы, основанные на классификации, могут не стоить будущих исследовательских усилий, поскольку новые модели GenAI, вероятно, будет сложнее распознать. Кроме того, подходы, основанные на классификации, очень чувствительны к распределению выходных данных модели, которые могут существенно различаться, представляя собой движущуюся цель при обнаружении контента. Кроме того, подход, основанный на классификации, может иметь недостатки в отношении неанглоязычного контента или редко встречающихся образцов во время обучения. Следовательно, создание водяных знаков может быть более перспективным направлением, чем методы, основанные на классификации.
Мы представляем несколько потенциальных направлений будущих исследований.
- •Водяные знаки в моделях с открытым исходным кодом: Неясно, как ставить водяные знаки в моделях с открытым исходным кодом, поскольку злоумышленнику легко удалить любой код, специфичный для водяных знаков, или изменить веса и метод декодирования. Без практического способа нанесения водяных знаков на модели с открытым исходным кодом очень легко использовать модели с открытым исходным кодом для перефразирования контента с водяными знаками, созданного моделями с закрытым исходным кодом.
- •Нанесение водяных знаков на контент, созданный человеком: методы аутентификации изображений (Лу и Ляо, 2000, Куттер и др., 1997, Синха и Сингх, 2003), такие как подписание фотографий, сделанных цифровыми камерами, намекают на возможность создания специальных водяных знаков для контента, созданного человеком. Этот подход может предложить альтернативный или дополнительный метод для различения контента, созданного человеком, и контента, созданного машиной, добавляя еще один уровень к процессам аутентификации контента. Такой двойной подход, ориентированный как на машинную, так и на человеческую проверку контента, мог бы значительно повысить надежность систем проверки контента.
- •Межмодельная координация: Решающее значение имеет обеспечение эффективности механизмов создания водяных знаков в различных моделях и поколениях технологий искусственного интеллекта. Для этого требуется единый метод создания водяных знаков, приемлемый для всех поставщиков моделей.
3.5 Обеспечение соблюдения нормативных актов
Политика и нормативные акты потенциально могут сыграть роль в снижении рисков, связанных со злоупотреблением GenAI. Исследователи могут оказывать влияние, делая реалистичные прогнозы относительно развития и эффекта GenAI и предлагая ряд вариантов политики для директивных органов. Мы предлагаем несколько соображений для политиков:
- •Регулирование патентованных моделей и моделей с открытым исходным кодом: Опираясь на “криптовойны” (Таскинсой, 2019, Джарвис, 2020), мы знаем, что чрезмерно строгие национальные нормативы могут быть контрпродуктивными, потенциально сдерживая инновации и замедляя внедрение полезных технологий, а не смягчая неблагоприятные последствия новых технологий. Это наблюдение особенно актуально в контексте проприетарных моделей с открытым исходным кодом в области генеративного ИИ (GenAI). Запатентованные модели, возможно, легче регулировать, поскольку существует всего несколько компаний, которые необходимо было бы контролировать, но они в значительной степени зависят от ответственной и этичной практики этих компаний. Открытые модели допускают нерегулируемое использование и неконтролируемые модификации, но способствуют быстрым инновациям и поддерживают исследования по повышению безопасности искусственного интеллекта. Политика должна учитывать проблемы и преимущества, предоставляемые каждым типом модели, с целью достижения баланса между стимулированием инноваций и обеспечением безопасности.
- •Государственное лицензирование компаний LLM: Одним из подходов может быть государственное лицензирование компаний, разрабатывающих большие языковые модели (LLM). Это могло бы создать структурированную основу для подотчетности, надзора и соблюдения этических норм, тем самым повысив надежность систем GenAI.
- •Динамичная эволюция политики: Учитывая быстрое развитие технологии GenAI, политика и регулирование потребуют регулярных обновлений для адаптации к новым технологическим реалиям и вызовам.
3.6 Эволюционирующее управление угрозами
Угрозы GenAI, как и все технологические угрозы, не стоят на месте. Мы сталкиваемся с игрой в кошки-мышки, где на каждый защитный ход злоумышленники разрабатывают ответный ход. Таким образом, системы безопасности должны постоянно развиваться, извлекая уроки из прошлых нарушений и предвосхищая будущие стратегии. Как и в случае с примерами состязательности для компьютерного зрения (Tramer et al., 2020), универсальной защиты от быстрого внедрения, джейлбрейков или других атак не существует, поэтому на данный момент одной прагматичной защитой может быть мониторинг и обнаружение угроз. Разработчикам понадобятся инструменты для мониторинга, обнаружения атак на GenAI и реагирования на них, а также стратегия анализа угроз для отслеживания новых возникающих угроз.
У общества были тысячи лет, чтобы придумать способы защиты от мошенников; GenAIs существуют всего несколько лет, поэтому мы все еще выясняем, как их защитить. Предсказать точную природу будущих угроз ИИ непросто. Исследователи активно исследуют новые контрмеры для защиты от угроз на GenAI. Поэтому мы рекомендуем разработчикам проектировать системы таким образом, чтобы сохранить гибкость на будущее, чтобы можно было внедрять новые средства защиты по мере их обнаружения.
Благодарности
Это исследование было поддержано Национальным научным фондом в рамках грантов 2229876 (центр ДЕЙСТВИЙ) и 2154873, стипендии для выпускников NSF, OpenAI, C3.ai DTI, Open Philanthropy, Google, Министерство внутренней безопасности и IBM.
Более широкие последствия
Наша работа исследует угрозы, с которыми может столкнуться общество и технологи. Мы считаем, что понимание будущих рисков отвечает общественным интересам, чтобы исследовательское сообщество могло приступить к разработке новых методов снижения этих рисков. Мы также набрасываем дорожную карту направлений будущих исследований, которые, по нашему мнению, являются перспективными для устранения ряда этих рисков.
Ссылки
- Ааронсон (2022) С. Ааронсон. Моя лекция по безопасности искусственного интеллекта, посвященная эффективному альтруизму. Оптимизировано для местечка: блог Скотта Ааронсона. Проверено сентября, 11:2023, 2022. URL https://scottaaronson.blog/?p=6823.
- Алавида и др. (2023) М. Алавида, Б. А. Шавар, О. И. Абиодун, А. Мехмуд, А. Э. Омолара и др. Раскрываем темную сторону ChatGPT: исследуем кибератаки и повышаем осведомленность пользователей. Информация, 15 февраля 2023 года.
- Антропный (2023) Антропный. Карточка модели и оценки для Claude Models, 2023. URL https://www-files.anthropic.com/production/images/Model-Card-Claude-2.pdf. Дата обращения: 27 сентября 2023 г.
- Асаре и др. (2023) О. Асаре, М. Нагаппан и Н. Асокан. Является ли второй пилот Github таким же плохим специалистом по внедрению уязвимостей в код, как и люди? Эмпирическая разработка программного обеспечения , 28(6):1-24, 2023.
- Азария и Митчелл (2023) А. Азария и Т. Митчелл. Внутреннее состояние магистра права Знает, когда он лжет, 2023. arXiv: 2304.13734.
- Бай и др. (2022) Ю. Бай, А. Джонс, К. Ндусс, А. Аскелл, А. Чен, Н. ДасСарма, Д. Дрейн, С. Форт, Д. Гангули, Т. Хениган и др. Обучение полезного и безвредного помощника с подкреплением на основе обратной связи с человеком. Препринт arXiv arXiv: 2204.05862, 2022.
- Беткер и др. (2023) Дж. Беткер, Г. Го, Л. Цзин, Т. Брукс, Дж. Ван, Л. Ли, Л. Оуян, Дж. Чжуан, Дж. Ли, Ю. Го и др. Улучшение генерации изображений за счет улучшения подписей. Информатика. https://cdn. openai. com/документы/dall-e-3. pdf, 2023.
- Боммазани и др. (2021) Р. Боммазани, Д. А. Хадсон, Э. Адели, Р. Альтман, С. Арора, С. фон Аркс, М. С. Бернштейн, Дж. Богг, А. Босселут, Э. Бранскилл и др. О возможностях и рисках базовых моделей. Препринт arXiv arXiv: 2108.07258, 2021.
- Бранч и др. (2022) Х. Дж. Бранч, Дж. Р. Чефалу, Дж. Макхью, Л. Худжер, А. Бахль, Д. д. К. Иглесиас, Р. Хейхман и Р. Дарвиши. Оценка уязвимости предварительно обученных языковых моделей с помощью созданных вручную состязательных примеров. Препринт arXiv arXiv: 2209.02128, 2022.
- Браун и др. (2020) Т. Браун, Б. Манн, Н. Райдер, М. Суббиах, Дж. Д. Каплан, П. Дхаривал, А. Нилакантан, П. Шьям, Г. Састри, А. Аскелл и др. Языковые модели изучаются редко. Достижения в области нейронных систем обработки информации, 33: 1877-1901, 2020.
- Бубек и др. (2023) С. Бубек, В. Чандрасекаран, Р. Элдан, Дж. Герке, Э. Хорвиц, Э. Камар, П. Ли, Ю. Т. Ли, Ю. Ли, С. Лундберг и др. Искры общего искусственного интеллекта: ранние эксперименты с gpt-4. Препринт arXiv arXiv: 2303.12712, 2023.
- Carlini et al. (2023) N. Carlini, M. Jagielski, C. A. Choquette-Choo, D. Paleka, W. Pearce, H. Anderson, A. Terzis, K. Thomas, and F. Tramèr. Poisoning web-scale training datasets is practical. arXiv preprint arXiv:2302.10149, 2023.
- Chao et al. (2023) P. Chao, A. Robey, E. Dobriban, H. Hassani, G. J. Pappas, and E. Wong. Jailbreaking black box large language models in twenty queries. arXiv preprint arXiv:2310.08419, 2023.
- Chowdhery et al. (2022) A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmann, et al. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022.
- Christ et al. (2023) M. Christ, S. Gunn, and O. Zamir. Undetectable watermarks for language models. arXiv preprint arXiv:2306.09194, 2023.
- Christiano et al. (2023) P. Christiano, J. Leike, T. B. Brown, M. Martic, S. Legg, and D. Amodei. Deep reinforcement learning from human preferences, 2023. arXiv:1706.03741.
- Driess et al. (2023) D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, et al. Palm-e: An embodied multimodal language model. arXiv preprint arXiv:2303.03378, 2023.
- Felt et al. (2012) A. P. Felt, S. Egelman, M. Finifter, D. Akhawe, and D. Wagner. How to ask for permission. In HotSec 2012, 2012.
- Fu et al. (2023) Y. Fu, P. Liang, A. Tahir, Z. Li, M. Shahin, and J. Yu. Security weaknesses of copilot generated code in github. arXiv preprint arXiv:2310.02059, 2023.
- Ganguli et al. (2022) D. Ganguli, L. Lovitt, J. Kernion, A. Askell, Y. Bai, S. Kadavath, B. Mann, E. Perez, N. Schiefer, K. Ndousse, et al. Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned. arXiv preprint arXiv:2209.07858, 2022.
- Gao et al. (2023) L. Gao, J. Schulman, and J. Hilton. Scaling laws for reward model overoptimization. In International Conference on Machine Learning, pages 10835–10866. PMLR, 2023.
- Glukhov et al. (2023) D. Glukhov, I. Shumailov, Y. Gal, N. Papernot, and V. Papyan. LLM Censorship: A Machine Learning Challenge or a Computer Security Problem? arXiv preprint arXiv:2307.10719, 2023.
- Greshake et al. (2023a) K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz. More than you’ve asked for: A comprehensive analysis of novel prompt injection threats to application-integrated large language models. arXiv e-prints, pages arXiv–2302, 2023a.
- Greshake et al. (2023b) K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz. Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection. In Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security, pages 79–90, 2023b.
- Gupta et al. (2023) M. Gupta, C. Akiri, K. Aryal, E. Parker, and L. Praharaj. From ChatGPT to ThreatGPT: Impact of Generative AI in Cybersecurity and Privacy. IEEE Access, 2023.
- Huang et al. (2023) B. Huang, B. Zhu, H. Zhu, J. D. Lee, J. Jiao, and M. I. Jordan. Towards optimal statistical watermarking. arXiv preprint arXiv:2312.07930, 2023.
- Iqbal et al. (2023) U. Iqbal, T. Kohno, and F. Roesner. LLM Platform Security: Applying a Systematic Evaluation Framework to OpenAI’s ChatGPT Plugins, 2023. arXiv:2309.10254.
- Ivison et al. (2023) H. Ivison, Y. Wang, V. Pyatkin, N. Lambert, M. Peters, P. Dasigi, J. Jang, D. Wadden, N. A. Smith, I. Beltagy, and H. Hajishirzi. Camels in a changing climate: Enhancing lm adaptation with tulu 2, 2023.
- Jarvis (2020) C. Jarvis. Crypto wars: the fight for privacy in the digital age: A political history of digital encryption. CRC Press, 2020.
- Kirchenbauer et al. (2023) J. Kirchenbauer, J. Geiping, Y. Wen, J. Katz, I. Miers, and T. Goldstein. A watermark for large language models. arXiv preprint arXiv:2301.10226, 2023.
- Kuditipudi et al. (2023) R. Kuditipudi, J. Thickstun, T. Hashimoto, and P. Liang. Robust distortion-free watermarks for language models. arXiv preprint arXiv:2307.15593, 2023.
- Kutter et al. (1997) M. Kutter, F. D. Jordan, and F. Bossen. Digital signature of color images using amplitude modulation. In Storage and Retrieval for Image and Video Databases V, volume 3022, pages 518–526. SPIE, 1997.
- Liu et al. (2023a) H. Liu, C. Li, Q. Wu, and Y. J. Lee. Visual instruction tuning. arXiv preprint arXiv:2304.08485, 2023a.
- Liu et al. (2023b) T. Liu, Y. Zhao, R. Joshi, M. Khalman, M. Saleh, P. J. Liu, and J. Liu. Statistical rejection sampling improves preference optimization. arXiv preprint arXiv:2309.06657, 2023b.
- Liu et al. (2023c) Y. Liu, G. Deng, Y. Li, K. Wang, T. Zhang, Y. Liu, H. Wang, Y. Zheng, and Y. Liu. Prompt Injection attack against LLM-integrated Applications. arXiv preprint arXiv:2306.05499, 2023c.
- Liu et al. (2023d) Y. Liu, G. Deng, Z. Xu, Y. Li, Y. Zheng, Y. Zhang, L. Zhao, T. Zhang, and Y. Liu. Jailbreaking ChatGPT via Prompt Engineering: An Empirical Study, 2023d. arXiv:2305.13860.
- Lu and Liao (2000) C.-S. Lu and H.-Y. M. Liao. Structural digital signature for image authentication: an incidental distortion resistant scheme. In Proceedings of the 2000 ACM workshops on Multimedia, pages 115–118, 2000.
- Lv et al. (2023) K. Lv, W. Zhang, and H. Shen. Supervised fine-tuning and direct preference optimization on intel gaudi2 — by intel(r) neural compressor — intel analytics software — nov, 2023 — medium. https://medium.com/intel-analytics-software/the-practice-of-supervised-finetuning-and-direct-preference-optimization-on-habana-gaudi2-a1197d8a3cd3, 2023. (Accessed on 01/12/2024).
- Markov et al. (2023) T. Markov, C. Zhang, S. Agarwal, F. E. Nekoul, T. Lee, S. Adler, A. Jiang, and L. Weng. A holistic approach to undesired content detection in the real world. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 15009–15018, 2023.
- Monje et al. (2023) A. Monje, A. Monje, R. A. Hallman, and G. Cybenko. Being a bad influence on the kids: Malware generation in less than five minutes using ChatGPT, 2023.
- Morris et al. (2023) M. R. Morris, J. Sohl-dickstein, N. Fiedel, T. Warkentin, A. Dafoe, A. Faust, C. Farabet, and S. Legg. “Levels of AGI”: Operationalizing Progress on the Path to AGI, 2023. arXiv:2311.02462.
- Mudgal et al. (2023) S. Mudgal, J. Lee, H. Ganapathy, Y. Li, T. Wang, Y. Huang, Z. Chen, H.-T. Cheng, M. Collins, T. Strohman, et al. Controlled decoding from language models. arXiv preprint arXiv:2310.17022, 2023.
- Narayanan (2008) A. Narayanan. Lendingclub.com: A de-anonymization walkthrough, 2008. https://33bits.wordpress.com/2008/11/12/57/.
- Narayanan and Shmatikov (2010) A. Narayanan and V. Shmatikov. Myths and fallacies of” personally identifiable information”. Communications of the ACM, 53(6):24–26, 2010.
- Narayanan et al. (2016) A. Narayanan, J. Huey, and E. W. Felten. A precautionary approach to big data privacy. Data protection on the move: Current developments in ICT and privacy/data protection, pages 357–385, 2016.
- Nasr et al. (2023) M. Nasr, N. Carlini, J. Hayase, M. Jagielski, A. F. Cooper, D. Ippolito, C. A. Choquette-Choo, E. Wallace, F. Tramèr, and K. Lee. Scalable extraction of training data from (production) language models. arXiv preprint arXiv:2311.17035, 2023.
- OpenAI (2023) OpenAI. Gpt-4 technical report, 2023.
- Ouyang et al. (2022) L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- Pa Pa et al. (2023) Y. M. Pa Pa, S. Tanizaki, T. Kou, M. Van Eeten, K. Yoshioka, and T. Matsumoto. An Attacker’s Dream? Exploring the Capabilities of ChatGPT for Developing Malware. In Proceedings of the 16th Cyber Security Experimentation and Test Workshop, pages 10–18, 2023.
- Perez and Ribeiro (2022) F. Perez and I. Ribeiro. Ignore previous prompt: Attack techniques for language models. arXiv preprint arXiv:2211.09527, 2022.
- Phute et al. (2023) M. Phute, A. Helbling, M. Hull, S. Peng, S. Szyller, C. Cornelius, and D. H. Chau. LLM Self Defense: By Self Examination, LLMs Know They Are Being Tricked, 2023. arXiv:2308.07308.
- Qin et al. (2022) L. Qin, S. Welleck, D. Khashabi, and Y. Choi. Cold decoding: Energy-based constrained text generation with langevin dynamics. Advances in Neural Information Processing Systems, 35:9538–9551, 2022.
- Radford et al. (2019) A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- Radford et al. (2021) A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- Ramesh et al. (2021) A. Ramesh, M. Pavlov, G. Goh, S. Gray, C. Voss, A. Radford, M. Chen, and I. Sutskever. Zero-shot text-to-image generation. In International Conference on Machine Learning, pages 8821–8831. PMLR, 2021.
- Rando and Tramèr (2023) J. Rando and F. Tramèr. Universal jailbreak backdoors from poisoned human feedback. arXiv preprint arXiv:2311.14455, 2023.
- Rateike et al. (2023) M. Rateike, C. Cintas, J. Wamburu, T. Akumu, and S. Speakman. Weakly Supervised Detection of Hallucinations in LLM Activations. arXiv preprint arXiv:2312.02798, 2023.
- Renaud et al. (2023) K. Renaud, M. Warkentin, and G. Westerman. From ChatGPT to HackGPT: Meeting the Cybersecurity Threat of Generative AI. MIT Sloan Management Review, 2023.
- Schick et al. (2023) T. Schick, J. Dwivedi-Yu, R. Dessì, R. Raileanu, M. Lomeli, L. Zettlemoyer, N. Cancedda, and T. Scialom. Toolformer: Language models can teach themselves to use tools. arXiv preprint arXiv:2302.04761, 2023.
- Schulman et al. (2022) J. Schulman, B. Zoph, C. Kim, J. Hilton, J. Menick, J. Weng, J. F. C. Uribe, L. Fedus, L. Metz, M. Pokorny, et al. ChatGPT: Optimizing language models for dialogue. OpenAI blog, 2022.
- Sebastian (2023) G. Sebastian. Privacy and Data Protection in ChatGPT and Other AI Chatbots: Strategies for Securing User Information, 2023. SSRN 4454761.
- Sinha and Singh (2003) A. Sinha and K. Singh. A technique for image encryption using digital signature. Optics communications, 218(4-6):229–234, 2003.
- Song et al. (2020) Y. Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456, 2020.
- Stiennon et al. (2020) N. Stiennon, L. Ouyang, J. Wu, D. Ziegler, R. Lowe, C. Voss, A. Radford, D. Amodei, and P. F. Christiano. Learning to summarize with human feedback. Advances in Neural Information Processing Systems, 33:3008–3021, 2020.
- Taskinsoy (2019) J. Taskinsoy. Facebook’s libra: Why does us government fear price stable cryptocurrency? Available at SSRN 3482441, 2019.
- Team (2023) O. Team. GPT-4V(ision) System Card, 2023.
- ThankGod Chinonso (2023) E. ThankGod Chinonso. The impact of ChatGPT on privacy and data protection laws, 2023. SSRN 4574016.
- Touvron et al. (2023) H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- Toyer et al. (2023) S. Toyer, O. Watkins, E. A. Mendes, J. Svegliato, L. Bailey, T. Wang, I. Ong, K. Elmaaroufi, P. Abbeel, T. Darrell, et al. Tensor trust: Interpretable prompt injection attacks from an online game. arXiv preprint arXiv:2311.01011, 2023.
- Tramer et al. (2020) F. Tramer, N. Carlini, W. Brendel, and A. Madry. On adaptive attacks to adversarial example defenses. Advances in neural information processing systems, 33:1633–1645, 2020.
- Venugopal et al. (2011) A. Venugopal, J. Uszkoreit, D. Talbot, F. J. Och, and J. Ganitkevitch. Watermarking the outputs of structured prediction with an application in statistical machine translation. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, pages 1363–1372, 2011.
- Wang et al. (2023) G. Wang, S. Cheng, X. Zhan, X. Li, S. Song, and Y. Liu. Openchat: Advancing open-source language models with mixed-quality data. arXiv preprint arXiv:2309.11235, 2023.
- Wei et al. (2023) A. Wei, N. Haghtalab, and J. Steinhardt. Jailbroken: How does llm safety training fail? arXiv preprint arXiv:2307.02483, 2023.
- Wei et al. (2022a) J. Wei, Y. Tay, R. Bommasani, C. Raffel, B. Zoph, S. Borgeaud, D. Yogatama, M. Bosma, D. Zhou, D. Metzler, et al. Emergent abilities of large language models. arXiv preprint arXiv:2206.07682, 2022a.
- Wei et al. (2022b) J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, D. Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837, 2022b.
- Wu et al. (2023) X. Wu, R. Duan, and J. Ni. Unveiling security, privacy, and ethical concerns of ChatGPT. Journal of Information and Intelligence, 2023.
- Yang and Klein (2021) K. Yang and D. Klein. Fudge: Controlled text generation with future discriminators. arXiv preprint arXiv:2104.05218, 2021.
- Yang et al. (2023) L. Yang, Z. Zhang, Y. Song, S. Hong, R. Xu, Y. Zhao, W. Zhang, B. Cui, and M.-H. Yang. Diffusion models: A comprehensive survey of methods and applications. ACM Computing Surveys, 56(4):1–39, 2023.
- Zhang et al. (2019) X. Zhang, S. Karaman, and S.-F. Chang. Detecting and simulating artifacts in gan fake images. In 2019 IEEE international workshop on information forensics and security (WIFS), pages 1–6. IEEE, 2019.
- Zhao et al. (2023) X. Zhao, P. Ananth, L. Li, and Y.-X. Wang. Provable robust watermarking for ai-generated text. arXiv preprint arXiv:2306.17439, 2023.
- Zhu et al. (2023a) B. Zhu, E. Frick, T. Wu, H. Zhu, and J. Jiao. Starling-7b: Improving llm helpfulness & harmlessness with rlaif, 2023a.
- Zhu et al. (2023b) B. Zhu, J. Jiao, and M. I. Jordan. Principled reinforcement learning with human feedback from pairwise or �-wise comparisons. arXiv preprint arXiv:2301.11270, 2023b.
- Zhu et al. (2023c) B. Zhu, H. Sharma, F. V. Frujeri, S. Dong, C. Zhu, M. I. Jordan, and J. Jiao. Fine-tuning language models with advantage-induced policy alignment. arXiv preprint arXiv:2306.02231, 2023c.
- Ziegler et al. (2019) D. M. Ziegler, N. Stiennon, J. Wu, T. B. Brown, A. Radford, D. Amodei, P. Christiano, and G. Irving. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593, 2019.
Related Posts
Ценовые войны в сфере искусственного интеллекта: анализ текущих тенденций и стратегий

Искусственный интеллект в медицине: текущие применения, перспективы и новейшие разработки
