
За последние месяцы сообщество разработчиков больших языковых моделей с открытым исходным кодом (LLM) внесло огромный вклад в развитие модели. Однако выпуски с описанием веса моделей и обзорные технические отчеты не содержат достаточной информации, чтобы охватить сложность обучения в магистратуре, что препятствует открытости и прозрачности, механизмам, стоящим за надежными и инновационными исследованиями и наукой на протяжении десятилетий.
С этой целью мы рады представить LLM360 — инициативу по созданию LLM с открытым исходным кодом, которая способствует прозрачности, доверию и совместным исследованиям. При выпуске моделей под управлением LLM360 мы стремимся сделать все детали LLM доступными для всех.Большинство выпусков LLM с открытым исходным кодом включают веса моделей и результаты оценки. Однако часто требуется дополнительная информация, чтобы по-настоящему понять поведение модели, а эта информация обычно недоступна большинству исследователей. Следовательно, мы обязуемся опубликовать все промежуточные контрольные точки (до 360!), собранные во время обучения, все обучающие данные (и их сопоставление контрольным точкам), все собранные показатели (например, потери, норму градиента, результаты оценки) и весь исходный код для предварительной обработки данных и обучения модели. Эти дополнительные артефакты могут помочь исследователям и практикам глубже изучить процесс построения LLM и провести исследования, такие как анализ динамики модели. Мы надеемся, что LLM360 поможет сделать продвинутые LLM более прозрачными, стимулировать исследования в небольших лабораториях и улучшить воспроизводимость исследований в области искусственного интеллекта.Для начала мы выпускаем две модели под управлением LLM360: Amber-7B и CrystalCoder-7B, которые, как мы надеемся, олицетворяют дух разработки с открытым исходным кодом и прозрачного искусственного интеллекта.LLM360 — это совместная работа Petuum
Основой LLM360 является создание фреймворка, поощряющего открытость и исследовательское сотрудничество для больших языковых моделей. В настоящее время мы включаем все следующие артефакты, связанные с моделями семейства LLM360:
Частые промежуточные контрольные точки модели: Во время обучения регулярно собираются параметры модели и состояния оптимизатора. Эти артефакты могут дать ценную информацию для изучения динамики обучения LLM и того, как она масштабируется с учетом данных, а также позволяют возобновить обучение на различных этапах.Обучающие данные с полной последовательностью данных: Весь предварительно обработанный, маркированный обучающий набор данных полностью раскрыт и сделан общедоступным. Набор данных представлен в точном соответствии с этапами обучения.Исходный код: Весь используемый код, включая обработку данных, обучение, оценку и анализ.Журналы и показатели: Все журналы обучения, оценки и результаты анализа, собранные во время обучения, публикуются публично, также в соответствии с этапами обучения и последовательностью данных.Это только начало наших усилий в области открытого исходного кода, и мы намерены продолжать предоставлять больше деталей. Пожалуйста, не стесняйтесь сообщать нам то, что вы хотите знать! Мы рады получать отзывы сообщества, позволяющие постоянно совершенствовать и дополнять наши релизы.
Amber и CrystalCoder выпущены под управлением LLM360Первыми двумя моделями, которые будут выпущены под управлением LLM360, являются Amber и CrystalCoder. Amber — это LLM на английском языке 7B, а CrystalCoder — это LLM с кодом и текстом 7B.Обе модели выпущены по лицензии Apache 2.0.
Amber: повышение уровня знаний и прозрачности при предварительном обучении в магистратуреПервый в семействе Amber — английский LLM, обученный на 1,2 триллионах токенов, который работает аналогично LLaMA-7B, OpenLLaMA-v2-7B и превосходит Pythia-6,7B.
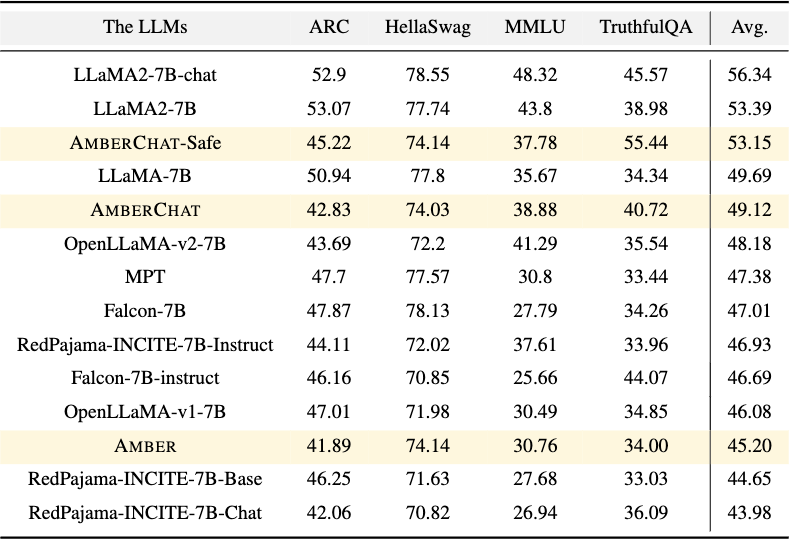
Рисунок: Сравнение открытой таблицы лидеров LLM среди нескольких известных LLMНастоящая сверхспособность Amber заключается в содействии обмену знаниями между командой тренингов и более широким сообществом. Наряду с обычными конечными весами моделей, Amber выпускается с 359 дополнительными контрольными точками модели (всего 360) и пошаговой последовательностью данных для каждой контрольной точки.Предоставление доступа к этим промежуточным контрольным точкам может быть полезным как исследователям, стремящимся расширить возможности и понимание LLM, так и отраслевым командам, которые проводят предварительное обучение или настраивают LLM для корпоративных целей.Мы опубликуем более подробную информацию из тренинга Amber, следите за дальнейшими публикациями!. На данный момент мы рекомендуем вам ознакомиться с показателями и анализом ниже.
CrystalCoder: соединение человеческого языка и машинного кодаCrystalCoder — это языковая модель 7B, обученная на 1,4 триллионах токенов, обеспечивающая баланс между кодированием и языковыми возможностями.
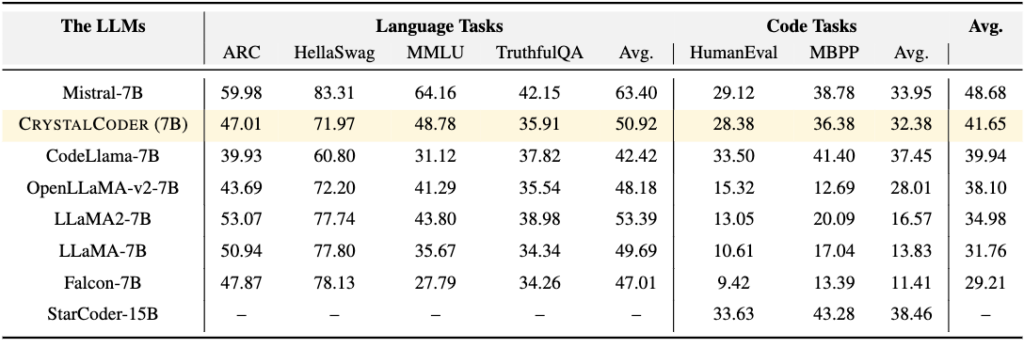
Таблица 5: Сравнение оценок между несколькими известными моделями кода и языка. Последний столбец представляет собой среднее значение средней языковой задачи и средней задачи кода. CrystalCoder обеспечивает хороший баланс между задачами языка и кода.
В отличие от большинства предыдущих code LLM, CrystalCoder обучается с использованием тщательного сочетания текста и данных кода для максимальной полезности в обеих областях. Данные кода вводятся раньше в процессе предварительной подготовки (по сравнению с Code Llama 2, который настраивается на Llama 2 с использованием исключительно данных кода). Кроме того, мы обучили CrystalCoder работе с Python и языком веб-программирования, чтобы улучшить его полезность в качестве помощника по программированию.Наши эксперименты показывают, что CystalCoder достигает сбалансированного положения между LLaMA 2 и Code LLaMA, но с меньшим количеством обучающих токенов (LLaMA2 7B обучается на токенах 2T, а Code LLaMA обучается с дополнительными токенами 600B). На приведенном ниже графике показаны языковые возможности и возможности кодирования каждой модели на основе приведенных выше таблиц. Как показывают оценки, языковые возможности LLaMA 2 ухудшаются при точной настройке кода. Для полного понимания феномена необходимы дополнительные исследования, но изучение CrystalCoder может дать некоторые идеи.
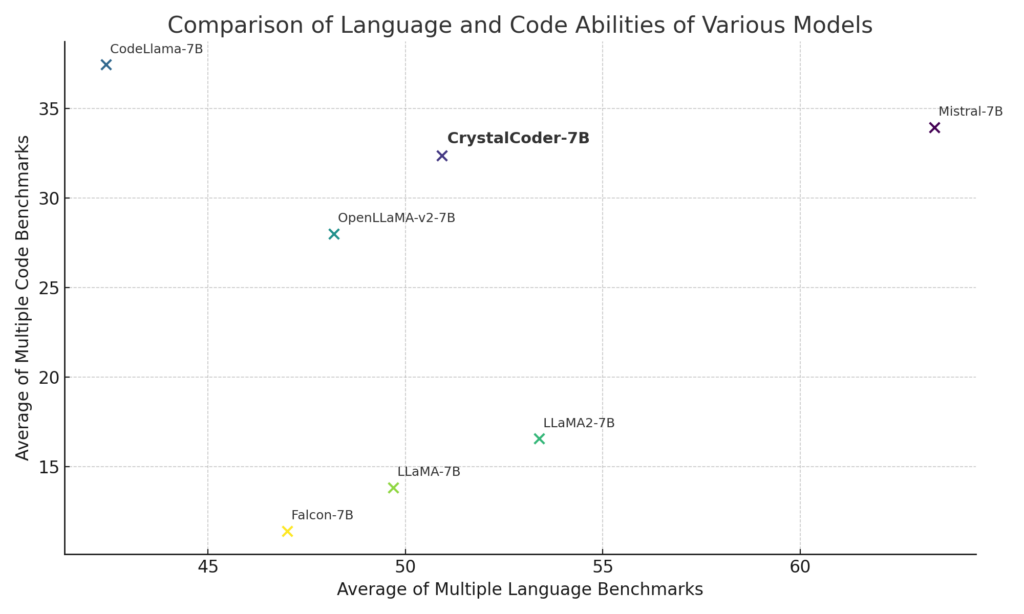
Благодаря превосходному знанию языка и кода CrystalCoder оказывается полезным для изучения возможностей использования агентов искусственного интеллекта и инструментов. CrystalCoder выпущен с 143 контрольными точками и всеми данными предварительной подготовки.Модель была обучена на суперкомпьютере Condor Galaxy 1, созданном Cerebras и G42.
Цели платформы LLM360Повышенная доступность:0 Графические процессоры: сообщество может просматривать все важные промежуточные результаты, как если бы обучение только что закончилось.Более 1 графических процессоров: промежуточные контрольные точки можно обучать без необходимости начинать с нуля, что открывает более широкие возможности для исследований.Продвижение исследований, воспроизводимость и понимание модели:Мы надеемся, что этот проект заложит основу для будущих исследований, предлагая полные, воспроизводимые ресурсы.Тиражируя исследования и проверяя результаты, мы создаем надежную и прозрачную исследовательскую среду.Экологическая ответственность:LLM360 способствует устойчивому проведению исследований, предоставляя доступ ко всем промежуточным результатам, которые могут быть расширены, тем самым сокращая ненужные вычисления.Сотрудничество и сообщество в LLM360Вклад в экосистему LLM360
LLM360 процветает благодаря вовлечению сообщества, предлагая исследователям, разработчикам и энтузиастам различные способы вовлечения и внесения вклада. Вот упрощенное руководство по вовлечению:
Участвуйте:GitHub: Наша страница на GitHub является центром для всего кода, связанного с LLM360. Изучайте, изменяйте или используйте наш код и вносите свои улучшения.HuggingFace: получите доступ к моделям LLM360 и загрузите их на HuggingFace. Экспериментируйте с ними и делитесь своими находками или приложениями.Поделитесь своей работой:Материалы для исследований: Если вы использовали Amber или CrystalCoder для исследований, мы рекомендуем вам поделиться своими результатами. Ваши идеи могут помочь улучшить эти модели.Делитесь результатами: Мы более чем приветствуем результаты вашего анализа на любой из контрольных точек. Не стесняйтесь делиться с нами вычисленными вами показателями, мы разместим выбранные показатели на нашей общедоступной панели весов и отклонений.Отзывы и предложения:Форма обратной связи: Мы ценим ваш вклад. Используйте эту форму, чтобы оставить отзыв или предложить улучшения. Дайте нам знать, что вы хотите узнать больше о LLM!Присоединяйтесь к дискуссиям: Общайтесь с коллегами на наших форумах. Делитесь опытом, задавайте вопросы и обменивайтесь идеями.СотрудничайтеВозможности партнерства: Если вы заинтересованы в сотрудничестве над проектом или у вас есть идея, мы будем рады услышать ваше мнение.Что ждет LLM360 впередиМиссия LLM360 заключается в расширении и углублении влияния исследований в области искусственного интеллекта путем предоставления полностью доступных LLM с открытым исходным кодом. Мы стремимся быть полностью открытыми и делиться более качественной информацией о LLM.Присоединяйтесь к нашему глобальному сообществу исследователей, разработчиков и энтузиастов искусственного интеллекта, чтобы изучать, улучшать и расширять модели в рамках LLM360. Вместе мы можем сделать исследования в области искусственного интеллекта более открытыми, прозрачными и заслуживающими доверия.
РесурсыRelated Posts
MIMO-EMBODIED ОТ XIAOMI: ЕДИНАЯ МОДЕЛЬ ДЛЯ АВТОНОМНОГО ВОЖДЕНИЯ И «ВОПЛОЩЁННОГО» ИИ

Искусственный интеллект на перепутье: Технологический прорыв, консолидация рынка и глобальные вызовы (06-11 мая 2025)